During sprint two of my capstone with PHS, I worked on finishing the update structure for LandCare Project shapefiles. As we were updating both parcels and sites, code was required for each subset of data. To streamline the process, I used metacoding like what was posted in my first blog post. There were two main processes that were coded in this sprint: address updates and the addition of whole new sites. Both will be discussed in this blog post.
I have found it best when explaining the parts of this project to think about parcels and sites as Lego bricks and structures respectively. Consider an individual Lego brick. Singularly it does a job and has a function, just as a land parcel does as a singular address. But, when parcels are added together they become sites that consist of multiple addresses. This could be considered to when several Lego bricks are combined to make a structure. There is still the ability to remove or add bricks but the overall geometry of the structure will change.
This is comparable to the address addition and removal process. As we add a new parcel or brick, we must also update the sites file as the geometry is changing. This is also true for the removal of a parcel. While the changes we are making may include only the addition of one small parcel or brick, the site geometry or structure changes significantly. This requires a special geometry update in SQL to ensure that these changes are not missed accidentally in a shapefile update.
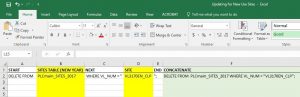
These address updates were broken into two separate metacoding files: address addition and address removal. Address addition utilized data for parcels from the Philadelphia Water Department to provide geometries for new parcels being added to sites. Each parcel was individually added to the parcels file first with the selection of the geometry and other unique fields from the PWD parcel data. Following, data was updated for the parcel file for the new address range. Other parcel information was copied from other parcels in the site we were interested in. The code for these parts has been pasted below.
INSERT INTO PLCmaint_parcels_2017 (ADDRESS, Geometry)
SELECT ADDRESS, Shape
FROM allparcels_517
WHERE ADDRESS = "1501 N 15TH ST";
UPDATE PLCmaint_parcels_2017
SET PARCELID = (SELECT PLCmaint_parcels_2017.PARCELID FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
TENCODE = (SELECT PLCmaint_parcels_2017.TENCODE FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
OWNER1 = (SELECT PLCmaint_parcels_2017.OWNER1 FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
OWNER2 = (SELECT PLCmaint_parcels_2017.OWNER2 FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
BLDG_CODE = (SELECT PLCmaint_parcels_2017.BLDG_CODE FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
BLDG_DESC = (SELECT PLCmaint_parcels_2017.BLDG_DESC FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
BRT_ID = (SELECT PLCmaint_parcels_2017.BRT_ID FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
GROSS_AREA = (SELECT PLCmaint_parcels_2017.GROSS_AREA FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
Shape_Area = (SELECT PLCmaint_parcels_2017.Shape_Area FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
PID = (SELECT PLCmaint_parcels_2017.PID FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
Year = (SELECT PLCmaint_parcels_2017.Year FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
Season = (SELECT PLCmaint_parcels_2017.Season FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
VL_Num = (SELECT PLCmaint_parcels_2017.VL_Num FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
Sq_Ft = (SELECT PLCmaint_parcels_2017.Sq_Ft FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
Trees_Num = (SELECT PLCmaint_parcels_2017.Trees_Num FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
TARGETAREA = (SELECT PLCmaint_parcels_2017.TARGETAREA FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
Grid = (SELECT PLCmaint_parcels_2017.Grid FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
CCD = (SELECT PLCmaint_parcels_2017.CCD FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
ZIPCODE = (SELECT PLCmaint_parcels_2017.ZIPCODE FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
Action = (SELECT PLCmaint_parcels_2017.Action FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
TARG_GRID = (SELECT PLCmaint_parcels_2017.TARG_GRID FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
CCD_Person = (SELECT PLCmaint_parcels_2017.CCD_Person FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST"),
Program = (SELECT PLCmaint_parcels_2017.Program FROM PLCmaint_parcels_2017 WHERE PLCmaint_parcels_2017.ADDRESS = "1503 N 15TH ST")
WHERE ADDRESS IN (
SELECT ADDRESS
FROM PLCmaint_parcels_2017
WHERE PLCmaint_parcels_2017.ADDRESS = "1501 N 15TH ST");
UPDATE PLCmaint_parcels_2017
SET NumParcels = "13",
Addr_Range = "1501 - 1507 N 15TH ST"
WHERE VL_Num = "VL0123EN_CLP";
Once parcel information was added and correct, the site shapefile geometry was updated accordingly. This was the product of a ST_Union function that inserted new geometries into the sites table in SpatiaLite. Address ranges and parcel numbers were updated accordingly as shown in the code block below.
UPDATE PLCmaint_SITES_2017
SET Geometry = (
SELECT ST_Union(Geomtery)
FROM PLCmaint_parcels_2017
GROUP BY VL_Num);
UPDATE PLCmaint_SITES_2017
SET NumParcels = "13",
Addr_Range = "1501 - 1507 N 15TH ST"
WHERE VL_Num = "VL0123EN_CLP";
Parcel removal required the copy of parcel data first to the New Use table so changes would be documented for the future. Once this was done, the parcel was deleted from the parcel table. The site geometry was updated following the same process as previously. Address ranges and parcel numbers were updated accordingly. This code can be visualized below for reference.
INSERT INTO NewUse_2017 (PARCELID, TENCODE, ADDRESS, OWNER1, OWNER2, BLDG_CODE, BLDG_DESC, BRT_ID, GROSS_AREA,
Shape_Area,VL_Num, Sq_Ft, Trees_Num, PID, TARGETAREA, Grid, CCD, Addr_Range, ZIPCODE, Geometry)
SELECT PARCELID, TENCODE, ADDRESS, OWNER1, OWNER2, BLDG_CODE, BLDG_DESC, BRT_ID, GROSS_AREA, Shape_Area, VL_Num,
Sq_Ft, Trees_Num, PID, TARGETAREA, GRID, CCD, Addr_Range, ZIPCODE, Geometry
FROM PLCmaint_parcels_2017
WHERE ADDRESS = "1501 N 15TH ST";
DELETE FROM PLCmaint_parcels_2017
WHERE ADDRESS = "1501 N 15TH ST";
UPDATE PLCmaint_parcels_2017
SET NumParcels = "12",
Addr_Range = "1503-1507 N 15TH ST"
WHERE VL_Num = "VL0123EN_CLP";
UPDATE PLCmaint_SITES_2017
SET Geometry = (
SELECT ST_Union(Geometry)
FROM PLCmaint_parcels_2017
GROUP BY VL_Num);
UPDATE PLCmaint_SITES_2017
SET NumParcels = "12",
Addr_Range = "1503-1507 N 15TH ST"
WHERE VL_Num = "VL0123EN_CLP";
Adding new sites entirely was a straightforward process. Four sections of metacoding were used to break down information and explain steps. The data was copied from provided shapefiles into the parcels table first, then the sites.
For the sites table update, the VL numbers (unique parcel identifier) were selected with a “SELECT DISTINCT” statement and these were copied into part three. This allowed for only the information for one parcel to be copied into the sites table, representing the data for the site that was available. Finally the site geometry was updated using the ST_Union feature described above. The code used is visible below.
INSERT INTO PLCmaint_parcels_2017 (PARCELID, TENCODE, ADDRESS, OWNER1, OWNER2, BLDG_CODE, BLDG_DESC, BRT_ID,
GROSS_AREA, Shape_Area, Year, Season, VL_Num, NumParcels, Sq_Ft, Trees_Num, TARGETAREA, Addr_Range, Geometry)
SELECT PARCELID, TENCODE, ADDRESS, OWNER1, OWNER2, BLDG_CODE, BLDG_DESC, BRT_ID, GROSS_AREA,Shape_Area, Year,
Season, VL_Num, NumParcels, Sq_Ft, Trees_Num, TARGETAREA, Addr_Range, Geometry)
FROM Fall16_Stabilization_parcels;
SELECT DISTINCT VL_Num
FROM Fall16_Stabilization_parcels;
INSERT INTO PLCmaint_SITES_2017 (VL_Num, ADDRESS, Year, Season, NumParcels, Sq_Ft, Trees_Num, TARGETAREA, Addr_Range, Geometry)
SELECT VL_Num, ADDRESS, Year, Season, NumParcels, Sq_Ft, Trees_Num, TARGETAREA, Addr_Range, Geometry
FROM Fall16_Stabilization_parcelsGROUP BY VL_Num HAVING VL_Num = "VL0123EN_CLP";
UPDATE PLCmaint_SITES_2017
SET Geometry = (
SELECT ST_Union(Geometry)
FROM PLCmaint_parcels_2017
GROUP BY VL_Num);
Any resulting data from these sections were queried to double check the work. My sprint three blog will cover the exporting of these tables to shapefiles and will use visualizations.