After the completion of my Geo-referencing tasks (years 1995, 1975, and 1959), I was given the option between more Geo-referencing (1965) or a slightly different route, which consisted of creating a method to classify land types and land uses. If it wasn’t obvious by the title, I chose Geo-referencing 1965…
Land classification is the method of determining what a feature is on imagery purely based on pixel value (pixel value can be interpreted differently depending on the situation). This allows for a colorful rendition and separation, which results in an easy to read and visualize context of where different features are located. Results can vary and are heavily reliant on image quality. The lower quality the image or imagery, the more generalization and inaccuracy of the classifications.
Anyway, land classification can be simple and it can also be quite difficult. If you are using tools that already exist, or software that are built to classify imagery, you can easily begin land classification/land use. If you are using preexisting material it will quickly become a matter of finding the right combination of numbers in order to get the classifications you want. This method is not too difficult, just more tedious in regards to acquiring your result. However, if you approach it from scratch, it will be significantly more engaging. In order to approach it from the bottom up, you have to essentially dissect the process. You have to analyze your imagery, extract pixel values, group the pixel values, combine all of them into a single file, and finally symbolize them based on attribution or pixel value which was recorded earlier. It is much easier said than done.
I am currently approaching the task via already created tools, however if I had a choice in the matter, I would have approached it via the bottom up method and attempted to create it from scratch as there is more learning in that and it is much more appealing to me. Regardless, I am creating info files, or files that contain the numbers, ranges, and classifications I am using to determine good land classifications. In contrast to what I stated earlier, this is quite difficult for me as the imagery is low quality and I am not a fan of continuously typing in ranges until I thread the needle.
The current tool I am using is the reclassify tool that is available through the ESRI suite and it requires the Spatial Analyst extension. This tool allows for the input of a single image, ranges you would like to use to classify the selected image, and output file. After much testing, I am pretty sure there can only be a maximum of 24 classifications (which is probably more than enough). In addition, the tool can be batch ran (as most ESRI tools can be), which means it can be run on multiple images at once. This is a much needed features for many situations, as I presume most times, individuals are not going to classify one image and be done (or at least I am not going to be one and done).

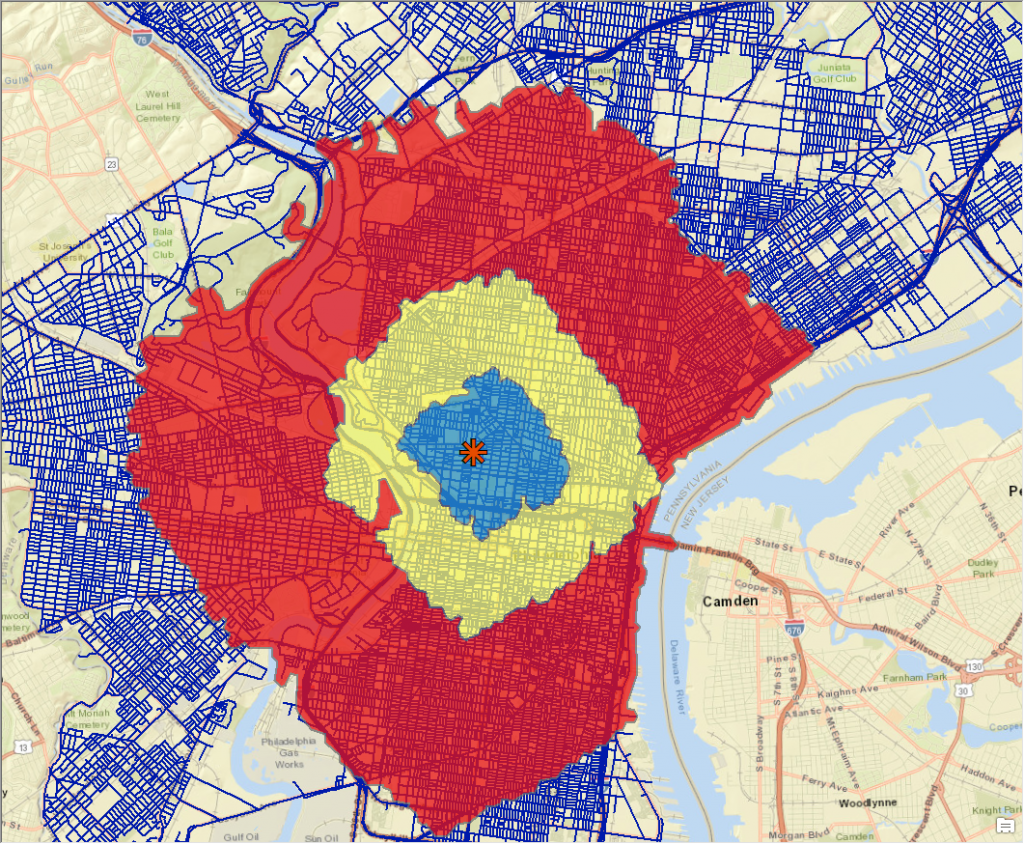
That is an image that was reclassified using the reclassify tool. I am not sure how good of a classification this is as I have not fully grasped the tool yet and every time I give it ranges, it spits out the same generic ranges that I did not input (which is a bit frustrating, but it comes with the territory). I am sure it is human error though and not the tool messing up. I am not sure what the final result is supposed to be, but I will be sure to fill you in once I achieve it (if I ever do…).