By Keisha Wiel
As part of my dissertation research, my project for the Digital Scholars Program looked at language attitudes about Papiamento/u on Facebook.
Papiamento/u, a language with fewer than 300,000 speakers worldwide, is spoken on the islands of Aruba, Bonaire, and Curaçao. It is a creole language comprised of some European languages, such as Spanish and Portuguese, African languages, such as Twi and Kimbundu, and traces of the Arawakan language family. My dissertation focuses on language socialization of ideologies and the construction of identity through education in Aruba and Curaçao. In particular, I look at the ways students are taught when and where to speak Papiamento/u and Dutch and, more concretely, what ideas about language use are getting passed on from teacher to students.
I also focus on how these ideologies are discussed on public Facebook pages. For this part of my dissertation, I want to explore whether these discussions about language have any correlation to discussions happening on the islands and whether these discussions have any correlation to language policies in education. The Digital Scholars program was instrumental in helping me to analyze data for this part of my research.
Finding my Data
I chose Facebook as the social media site to study because the most varied discussions about language and policies happened on Facebook compared to other sites such as Twitter. Discussions based on language attitudes, correct usage of the language, as well as how to write the language was much more frequent on Facebook. Parsing out these attitudes could potentially help understand how language policies on the islands are enacted in education. I specifically chose public Facebook pages that were either from an organization that focused on language and its issues, were a government page (such as the Facebook of the Ministry of Education), or news media pages (ranging from newspapers to blog pages). Through these pages, I looked for posts where language or language use was being discussed and used the Save feature in order to retrieve them for analysis.
Experimenting with Digital Tools
There were two major tools that I used in order to analyze my data. The first tool that I used was R to scrape data off of Facebook. Thanks to my illustrious mentor, Luling Huang, and his introduction to the program, I was able to learn the ins and outs of R. Through R, I was able to download and save the posts, their likes, and comment sections of each post into a file that I then coded into Excel and Word. I separated each thread, including post, comment to the post, and response to the comment, into individual columns so that I would be able to easily read and analyze the content. I also created a column for the likes appended to the comments, so I could analyze the popularity of the particular comment. Unfortunately, one of the limitations that I had working with R was scraping posts that contained diacritics and emojis. Since R could not scrape them, they came out as characters that I had to then manually change back into diacritics.
Once the data was cleaned and coded in Word, I uploaded the data into Voyant to analyze the word frequencies with the posts. One of the first things that I used to analyze the data was the Cirrus tool. I uploaded each post individually to see the word frequencies and whether particular words stood out in specific posts. The second tool that I used was the Phrases tool. I wanted to analyze whether there was certain phrase that were patterns throughout the posts. The third tool that I used was the Collocate tool. I wanted to see whether certain positive or negative words frequently collocated with certain phrases.
Analysis
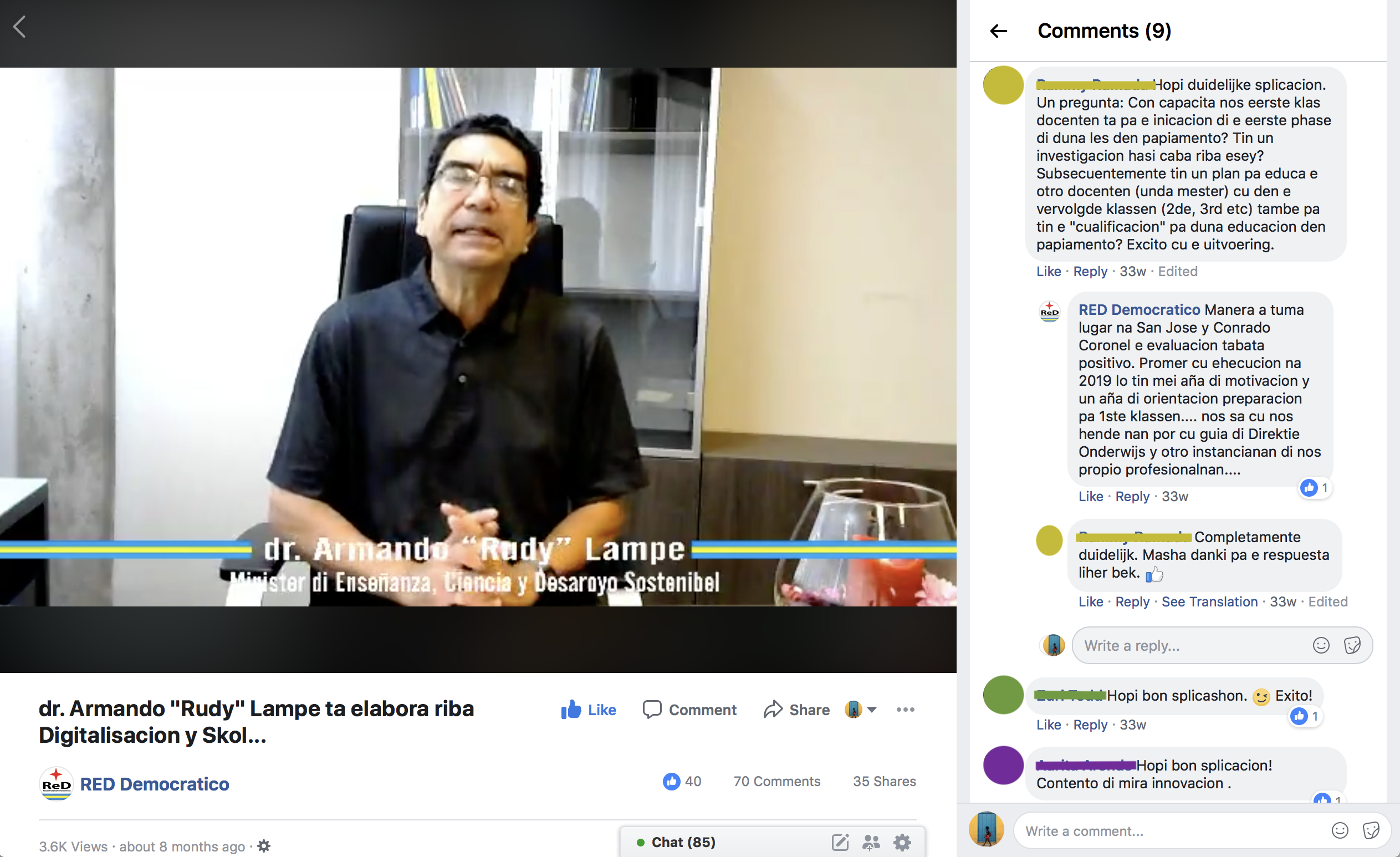
I wanted to research whether topical discussions about Papiamento/u were negative or positive on Facebook. Specifically, I wanted to observe whether certain posts would have specific reactions based on the topic being discussed. Through the Cirrus tool, I was able to notice that the main terms that frequently popped up in posts about language use were mainly words that would be used for correcting speech patterns. For instance, on a post that discussed a controversial word, the main words that were present were negative words. The word “no” was the most prominent word in the word cloud seen in the first image. But on posts about language as a cultural tool, positive words were more frequently present. For instance, on a post about local rapper, Jeon, using Papiamento/u on the internationally successful song “Machika” by J Balvin, words expressing gratitude and being proud of the language were used the most. This is evident in the second picture, where words like “proud”, “pabien” (congratulations), and “danki (thank you)” are more prominent.


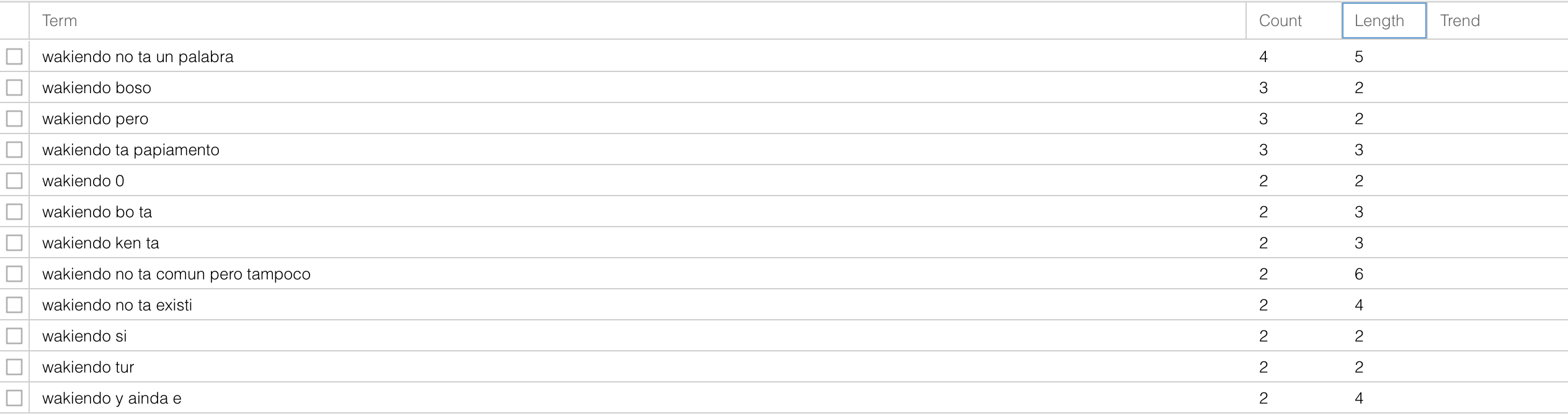
In the Phrases tool, I was able to notice that certain phrases about “correct” language popped up more frequently than phrases that didn’t correct language. For instance, in the same post about the controversial word, the phrase “wakiendo no ta un palabra” (wakiendo is not a word) showed up four times in the corpus. Although the corpus size is a sample of just 180 comments and its replies, it is telling that one of the most used phrases happened to be whether this particular word existed on the language. This is significant since ideologies about Papiamentu/o are often steeped in colonial ideas about its legitimacy.
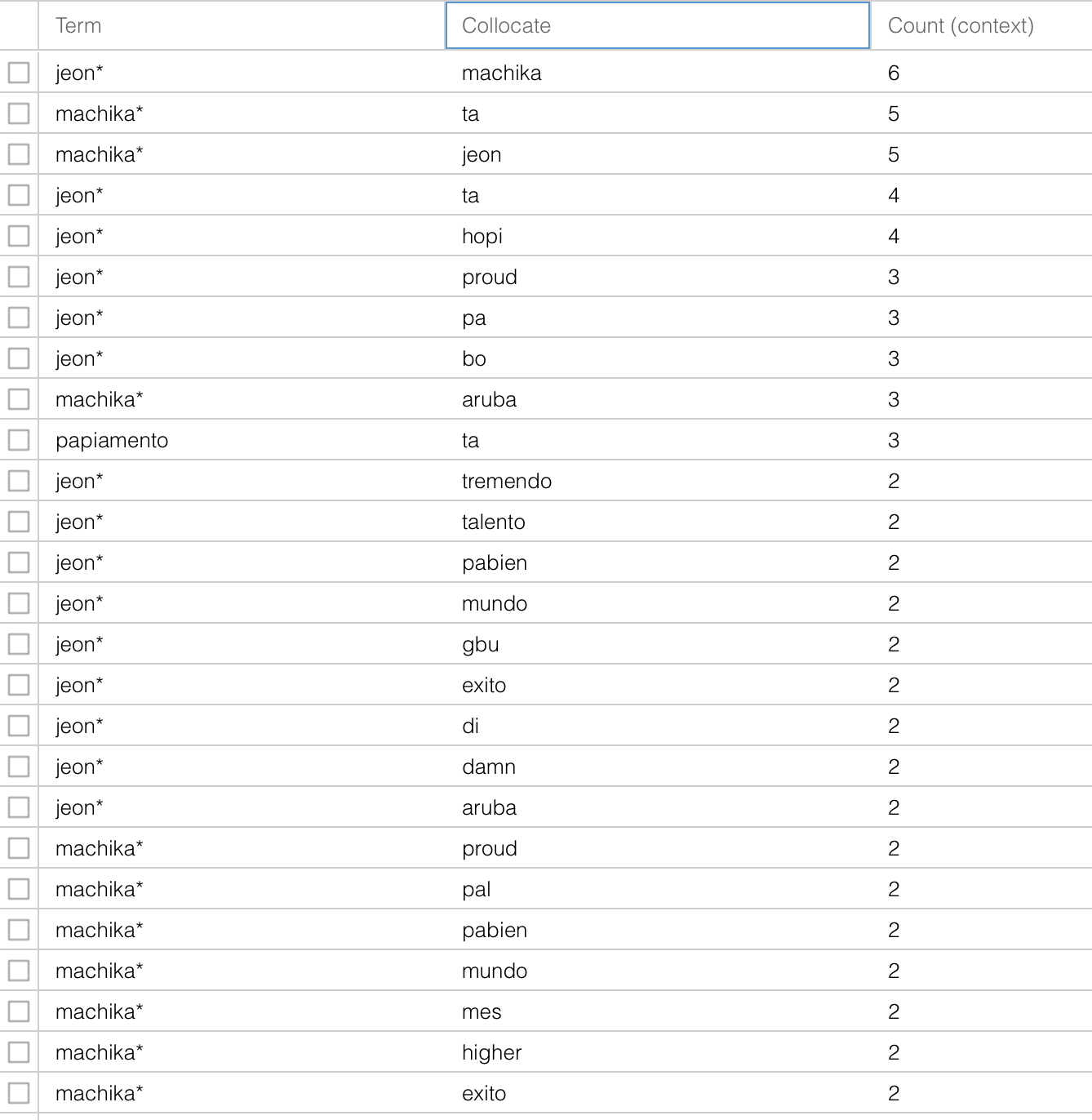
With the Collocate tool, I was really able to see how posts that dealt with language in popular culture seemed more positive than negative. For instance, in a post about a local singer using Papiamento/u in his song, words of encouragement were more frequently collocated with the singer’s name, the term “Papiamento”, and the song. This was in contrast to a post about a journalist who used a particular phrase that isn’t considered, by some, to be “correct” Papiamento/u. Negative words frequently collocated with her name, the language, and the particular phrase that she used.
Discussion
While this analysis only scratches the surface of the data, it does give insight into how discussions about language in Aruba and Curaçao are conducted on Facebook. As this will eventually be part of a larger study, the analysis of this data will be used as a starting point for further qualitative research into language attitudes on Facebook. This data also gives us a window into how speakers on the island are discussing their language, not only on Facebook but outside of the digital world. By continuing to gather data and analyzing it through these tools, I will eventually be able to discern through the research whether there is a correlation to between language attitudes and language policies in Aruba and Curaçao.
Thanks for share.