
By Luling Huang
The work done in Part I and Part II with OpenRefine applies to each thread in my data. My next goal is to complete the following three tasks with both OpenRefine and python:
A. Split the data based on unique values in the column “ThreadID;”
B. Do the cleaning work in Part I and Part II on one subset;
C. Apply the work done in “Task B” to other subsets.
The reason to include python is that it automates the process in Tasks A and C, which is especially important with a large dataset. Whereas my previous two blog posts speak more to my own project, I hope this one can be helpful for a more general situation when you want to automate the OpenRefine workflow on many subsets.
Needed tools:
I. OpenRefine;
II. pandas: a python library for processing dataframes (here is the link for installation);
III. refine-python: a client library for interacting with OpenRefine in python (here is the link for its GitHub page, and yes, it’s still working under OpenRefine 2.6).
Link for the hypothetical data used in this demonstration: Example_3Threads.csv (no longer available via Google Drive) (for simplification the time data is ready).
Task A:
What I thought I could do: Export subsets based on a facet of the column “ThreadID” in OpenRefine.
Is it possible to do? Yes. Although it is not an explicit functionality in OpenRefine, I found a workaround using Javascript provided by one developer. You can find the method here.
Problem: The code was written for exporting Excel files. It did not work when I changed “xls” to “csv” in the first two lines. Given the dire situation that I had zero knowledge in Javascript, for an easy workaround of the workaround, I turned to pandas in python.
Python code using pandas:
1 2 3 4 5 6 7 8 |
import pandas as pd test_df = pd.read_csv('Example_3Threads.csv') ThreadIDList = test_df.ThreadID.unique() root = 'SplitFiles' for i in ThreadIDList: spliti_df = test_df.loc[test_df['ThreadID'] == i] FileNamei = 'Example_3Threads-' + str(i) + '.csv' spliti_df.to_csv(root + '/' + FileNamei, index = False, encoding = 'utf-8') |
Line 2: Create a dataframe from the sample csv file.
Line 3: Create a list of unique values in the column “ThreadID.”
Line 4: Locate a subdirectory under the working directory to store all split files.
Lines 5 to 8: Loop through “ThreadIDList,” do the split, and export to csv with corresponding file names. The key is line 6: rows are selected based on values in the column “ThreadID.”
Result: Three split files based on thread IDs have been stored in the folder “SplitFiles.”
Task B:
In OpenRefine, do the work covered in Part II on any one of the subsets.
Task C:
OpenRefine stores every step that changes the data in an operation history. History of one project can be extracted, saved in JSON, and applied to other projects. Therefore, the logic of completing Task C is straightforward: C1. When Task B is finished, extract and save the history as JSON; C2. Use refine-python to automate the process of applying the operation history to the other two subsets.
C1: Extract operation history.
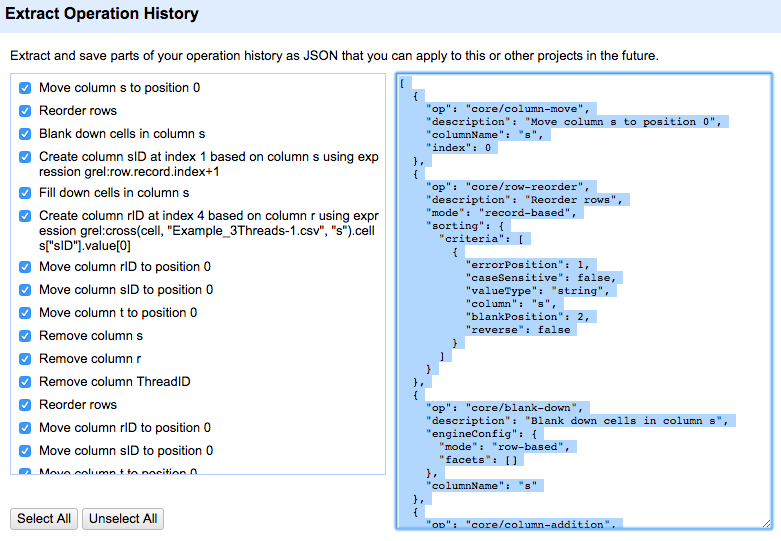
The left column lists all the steps performed in Task B. The right column shows the operation history in JSON. We can copy the JSON data to a code editor, and save it as “OperationHistory.json.”
C2: Let python streamline the remaining process.
Notes on directories for this demonstration: the working directory is “/python refine/,” where both “refine.py” and “OperationHistory.json” locate. Under “python refine,” “SplitFiles” stores split csv files from Task A, and “SplitFiles2” stores transformed csv files.
Python code with brief comments:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
# Load refine-python import sys sys.path.append("refine.py") import refine # Load other needed modules import json, os, re root = "SplitFiles" root2 = "SplitFiles2" # Loop through every csv file under the folder "SplitFiles" for filename in os.listdir(root): # Avoid annoying hidden files (.DS_Store in Mac OS X for example) if filename.endswith(".csv"): # Extract thread ID from file name filenameindex=filename.split("-")[1].split(".")[0] # Create an OpenRefine project r = refine.Refine() pfilename = r.new_project(filename) # Update JSON file ## 1. Read JSON file os.chdir("/Users/lulinghuang/Desktop/2016 DSC/openrefine/python refine/") jsonfilename=open("OperationHistory.json", "r") datafilename=json.load(jsonfilename) jsonfilename.close() ## 2. Change specific parts of content datafilename[5]["description"] = re.sub(r"(?<=-)\d+", filenameindex, datafilename[5]["description"]) datafilename[5]["expression"] = re.sub(r"(?<=-)\d+", filenameindex, datafilename[5]["expression"]) ## 3. Update jsonfilename=open("OperationHistory.json", "w") jsonfilename.write(json.dumps(datafilename)) jsonfilename.close() # Apply updated JSON to OpenRefine project pfilename.apply_operations("OperationHistory.json") # Export csv file to the folder "SplitFiles2" exportfilename="Thread" + "_" + str(filenameindex) + ".csv" os.chdir(root2) ffilename = open(exportfilename, "w") ffilename.write(pfilename.export_rows(format="csv")) ffilename.close() # Delete completed project pfilename.delete_project() # Reset directory for the loop os.chdir("/Users/lulinghuang/Desktop/2016 DSC/openrefine/python refine/") else: continue |
The tricky part (for me, may not apply to other situations):
In Part II (Step 6), there is a part of GREL’s cross() function that points to the working project’s name. Therefore, I have to update the JSON file in each loop so that the project names match. Lines 22-34 do this job (read, change, and update JSON).
More specifically, when python reads JSON, it converts JSON’s content to a list of dictionaries. Locating and changing parts of the JSON content thus follows the way such a list is structured (lines 29-30, the two places where project name needs to be changed locate in the keys “description” and “expression” under the sixth dictionary in the list).
More concretely, when “Example_3Threads-3.csv” enters the loop (the project name follows its file name by default), after line 34, the original project name in JSON, e.g., “Example_3Threads-689(whatever the index is).csv,” is changed to “Example_3Threads-3.csv.”