
By Luling Huang
Problem:
In R’s “relevent” (Butts, 2015), the identifiers of sender and receiver have to be integers, rather than strings. For example, if we have a sequence data with 12 ordered events like this:
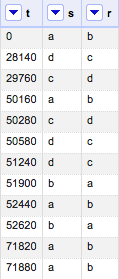
we need to assign “a,” “b,” “c,” and “d” to integers 1, 2, 3, and 4.
Assumption:
Receiver’s set R is a subset of sender’s set S.
Procedure:
1) Assign unique integers to objects in S.
2) Match objects in R to the assigned integers in S.
How to do it in OpenRefine:
1) Move the column “s” to beginning. That is, let the column be the first column from the left.
2) Sort the column “s” and reorder rows permanently.
3) Blank down “s” and switch to the “records” mode. The result is:
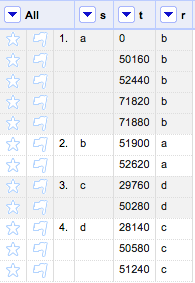
Similar cells in “s” become “records” under each unique value. The purpose of this step is to group values of “a,” “b,” “c,” and “d” with the row indexes 1, 2, 3, and 4 (imagine these numbers as group labels).
4) In “records” mode, for the column “s,” use “Edit column -> Add a column based on this column” to create a new column “sID.” Use the GREL expression “row.record.index+1.” Result:
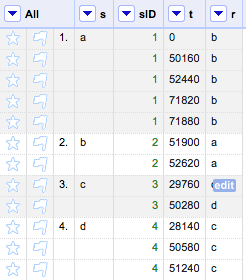
5) Fill down “s,” which is a reverse of Step 3. Result:
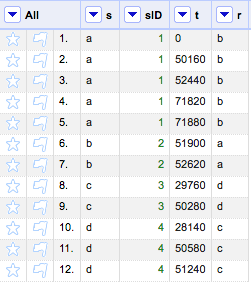
Now, Procedure 1 has been done. We have assigned unique integers to objects in S.
6) For the column “r,” use “Edit column -> Add a column based on this column” to create another new column “rID.” Use the GREL function “cross():”
![Description of step 6. The function used: cell.cross('sample4 csv', 's')[0].cells['sID'].value](https://sites.temple.edu/tudsc/files/2016/11/Screen-Shot-2016-11-28-at-11.55.07-AM.png)
The cross() function is written to match content of columns across different projects (e.g., different csv files). By designating the project name as the one we are working on, we can use cross() for our purpose: to match column values within one csv file.
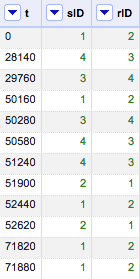
In cross(cell, “sample4 csv”, “s”).cells[“sID”].value[0], what we do is to first bind the two columns “s” and “sID” together (imagine the process as creating pairs of key-value in a dictionary); second, match the values in a third column, “r,” to “s;” third, assign values to a fourth column “rID” based on the matching chain of “s-sID-r.” Result (after sorting by time):
Feature image’s source: map by Martin Magdinier.
References
Butts, C. (2015). Package ‘relevent’ [R package documentation]. Retrieved from https://cran.r-project.org/web/packages/relevent/relevent.pdf
Wow! After all I gott a web site from where I can genuinely take helpfuul data concerning my study and knowledge.