By jay winkler
For many of us, adding “wiki” to the end of a Google search is like a cheat code for getting a quick answer. I know the structure of a Wikipedia article, and if I want an answer to a simple question, like “where was E.B. Lewis born”, just finding it on Wikipedia is the fastest way to get it.
But what about more complex questions? What if I wanted to know, say, who are all of the Black artists who were born in Philadelphia? For that, I can turn to Wikidata. Wikidata is an attempt to convert all of the world’s information into a structured, queryable dataset. There are Wikidata items for a huge range of topics and concepts. People, places, corporations, foods, animals, basketball teams, emotions, works of art, and just about anything else can have a Wikidata item.
In the second half of 2021 I worked with the Temple University Library as part of the LEADING Fellowship. Through a collaboration with the Philadelphia Museum of Art, our project mentors Synatra Smith, Alex Wermer-Colan, and Holly Tomren focused our project on updating and improving Wikidata’s collection of Black artists, and especially those from the Philadelphia area. I was also paired with a second LEADING fellow on this project Rebecca Y. Bayeck, CLIR postdoctoral Fellow in Data Curation at the Schomburg Center for Research in Black Culture. We developed a complicated query that enabled us to quickly collect a great deal of information about local artists. In this tutorial, I’ll discuss the building blocks of that query.
Wikidata Basics
Where Wikipedia has articles, Wikidata has “items.” Like I said above, an item can be anything that a Wikidata editor thinks people might want queryable structured data for. For each Wikidata item, statements can be added. These statements add properties of the item, such as “occupation”, “place of birth”, “race or ethnicity”, or other potential descriptors of the item. There are also properties for external identifiers, such as the items Virtual International Authority File catalog number. These properties are represented by triples: the item (1) has a property (2) with a given value (3).
Each Wikidata item is assigned a QID, which is a unique identifier that starts with a Q and ends with a number. The numbers are assigned sequentially, and have varying numbers of digits. Items then have a label. If you look at E.B. Lewis’s Wikidata item, the QID is Q5321733, and the human-readable English label is “E.B. Lewis”.
Using the QID as the primary identifier is useful for two main reasons. First, it allows for Wikidata items with duplicate labels (such as a band and their self-titled album or two identically named people) to be easily distinguishable, without the sort of parenthetical disambiguation common on Wikipedia. It also makes translation easier; as the whole Wikidata item does not need to be translated, just the label, while property labels can be updated individually.
Properties work similarly: each property has a property ID (PID) that can be used in queries. For many properties, the value also is a Wikidata item. For example, E.B. Lewis (Q5321733) has “occupation (P106)” property with the value “artist (Q483501)”. For other properties, the value can be a date, geographic coordinate, URL, or even an image. This is not an exhaustive list of potential property values. While anyone can create an item about anything, property creation does require a formal proposal and discussion with the Wikidata editor community. My colleague, Dr. Rebecca Y. Bayeck, has released a blog post in tandem with this one that goes deeper into editing Wikidata.
Basic Queries
Wikidata queries are built with SPARQL, a query language based on SQL. SPARQL makes it possible to query databases in the Research Data Framework (RDF) format, which are stored in triples. Queries can be typed directly into the Wikidata Query Service (WDQS), and there is also a SPARQL endpoint to collect data through Python.
The basic syntax for a SPARQL query is simple:
SELECT ?item ?itemLabel WHERE { ?item wdt:p# wd:q# SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". } }
To break this down: the SELECT statement tells the WDQS what variables we want to retrieve. In this case, we’ll retrieve the item, and because Wikidata will automatically return the QID for each item, we’ll also ask it to return the item’s label so our results are human readable.
The WHERE statement is where we put our conditions for what we want wikidata to return. In general, we’ll name a variable, and then say what properties that variable is required to have to be added to our list. If we want Wikidata to generate a list of all artists, the statement would look like this:
?item wdt:P106 wd:Q483501
“wdt” indicates a property, with P106 being the “occupation” property, and “wd” indicates we want the value of that property to be a specific Wikidata item, with Q484501 being the item for “artist”. So, we’re telling wikidata that to add an item to our list of items, it needs to have a statement with the occupation property, and that occupation’s value needs to be artist.
This query returns far too many results and may time out, so we’ll have to narrow it down a bit. Let’s look for artists from Philadelphia.
SELECT ?item ?itemLabel WHERE { ?item wdt:P106 wd:Q483501; wdt:P19 wd:Q1345 SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". } }
If we make our full query look like this, we return a much more manageable set of results. The semicolon indicates we’re still adding parameters for the item variable, and the second line indicates the parameters we’ve added: the item must have a P19 place of birth statement, which must be Q1345, Philadelphia. We can add more parameters to narrow what artists we want to return, and the basic list of Black artists from Philadelphia was the building block of our work in the LEADING fellowship.
The SERVICE statement tells WDQS that when we ask for labels, we want the English ones. No one needs to memorize this line of code, as WDQS’s tools make it very easy to add it automatically.
Retrieving More Variables
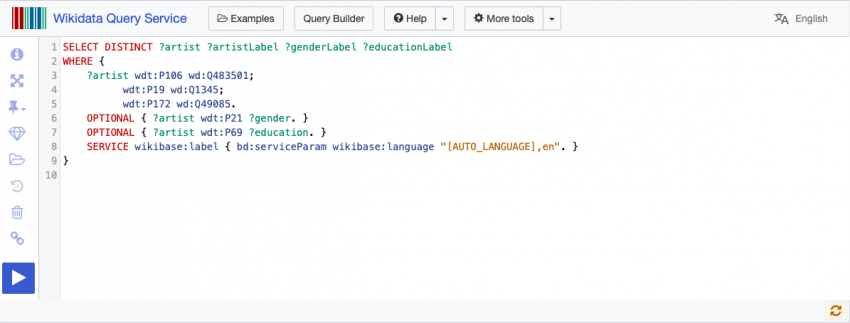
Let’s say we want to retrieve a few more variables. We don’t just want Black artists from Philadelphia, we want to know where those artists went to college and their gender. We do that by adding more variables to the SELECT statement, and then to the query itself. You can see our new query, and the rest of the full queries in this blog, directly on the Wikidata Query Service.
Our main focus here is the changes to the SELECT statement, and the corresponding changes to the query. We’ve changed our main variable from “?item” to “?artist”, just to make things a little easier on ourselves. We’ve also added two new variables that will become columns in our results: genderLabel and educationLabel.
In the query, we’ve added two lines that tell WDQS what to put in the new columns: for each artist, check for a P21 (which is the sex or gender property), and put the result in a column we’re calling gender. Do the same thing for P69, “educated at”, and put it in a column called education.
It is also important that in your SELECT statement you add “Label” to the end of your variables. So, if in the query you have the “Gender” variable, in the SELECT statement you want the variable to be “GenderLabel”. This way, your data will include the human-readable labels, and not the QIDs.
Let’s make one important change to our query.
I’ve now wrapped the requests for gender and education in the OPTIONAL tag and brackets. In the previous query, if an artist did not have either a P21 or a P69, they would simply be excluded from the dataset. By wrapping them in the optional tag, any artist that fits the parameters for the artist variable gets a row, and if it has a statement for gender or education, that gets included as well.
Concatenation
In the query above, both gender and education can potentially carry multiple statements. Many people were educated at multiple institutions, so both of those institutions are included in the results. Wikidata places these each in their own row, meaning several artists have multiple rows. We can fix this through concatenation.
Concatenation commands go before the WHERE statement. Each concatenation command replaces that variable in the SELECT statement:
SELECT ?artist ?artistLabel (group_concat(DISTINCT(?genderLabel);separator=", ") as ?genders) (group_concat(DISTINCT(?educationLabel);separator=", ") as ?educations)
Here I’ve removed the genderLabel and educationLabel variables and replaced them with two concatenation statements. I’ve asked WDQS to concatenate, I’ve asked it to only provide me distinct values so as to remove duplicates (this may occur when different sources are cited, for example), and I’ve asked it to use a comma followed by a space as a separator. I’ve also given the concatenated column its own name by pluralizing the main variable name.
Most of the WHERE statement is the same, but I do need to make a change to the SERVICE statement. This is due to a bug in WDQS that should be fixed eventually, but is consistent enough that most documentation will tell you to call in all of the labels manually:
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". ?artist rdfs:label ?artistLabel . ?gender rdfs:label ?genderLabel . ?education rdfs:label ?educationLabel . }
Finally, at the very end of my query, after the final curly bracket, I need to add a GROUP BY statement. You need to include every variable that is NOT being concatenated in your GROUP BY statement. If you are concatenating 2 out of your 14 variables, there needs to be 12 variables in your GROUP BY statement. Here, it looks like this:
GROUP BY ?artist ?artistLabel
Put it all together, and you get the full query, which is better looked at within the linked Wikidata Query service.
I’ve also added an ORDER BY statement so the data displays in alphabetical order.
Larger Statements
Now that we have the basics down, the queries are nearly endlessly extensible. To expand our Philadelphia Black artists dataset, we added a great number of variables.
In this query we’re able to gather artist names, birthplaces, residences, sexual orientation, employers, and some geographic coordinates using the same basic formula we used in the rest of our queries. I have cheated here: in the very first part of the WHERE statement we restrict results to a preselected list of artists. This prevents the system from timing out, but still gathers the dataset we’re looking for.
You can use these queries as the building blocks for your own queries. While the query just above might be complicated, try going back to the basic concatenated data, and replacing the QID for artists with a different occupation you’re interested in. Replace the city with one closer to you, and add some of the options in this final query to gather more data. There are many other SPARQL tricks, but these basics will hopefully help you understand how you can start from scratch on your own.
Next Steps
Developing the queries above required a great deal of trial and error, not only in the code, but in conceptualizing what exactly it was we wanted represented in our dataset. I would run the query, and find that while the code worked it lacked some piece of information that might be useful in drawing connections between these artists. In a forthcoming blog post, me and my colleague Rebecca will discuss how we used these results, to create visualizations using Python.