By Nicole Lemire Garlic
The number of videos uploaded to YouTube grows by the minute, and researchers are continuing to develop ways of critically engaging the large quantity of content housed on the platform. As noted by this introduction to using video for research, there are several social science and humanities-based approaches to studying videos, including cultural analytic approaches designed to analyze big video data. Cultural analytic approaches may look for visual patterns and disruptions in videos or across genres of videos.
For those approaches that require close viewing, computational text analysis of YouTube transcripts can help researchers zero in on salient videos.
Exploring YouTube Videos through Transcription
As explained in my prior post, YouTube is multimodal. There are several aspects of YouTube videos that can be distinctly analyzed: visual imagery, metadata about the video (such as duration and author), soundtracks (and sounds), and transcripts. The user comments and advertising that appear on the same page as the video may be analyzed as well. Ultimately, any attempt at drawing meaning from YouTube must consider all aspects. But, for analytical purposes, it can be useful to separate out a single aspect at a time.
One way to explore the content of the videos is through their transcripts. Focusing on the video transcripts opens the door for computational textual analysis tools that can be used to search for word correlations, frequently used words or phrases, and topics. These computational text analysis tools can help narrow down which videos are worth more in-depth exploration through close-reading analyses like social semiotics/multimodal research conducted in digital contexts.
The sort of flattening that comes with reducing videos to text has consequences, of course. Computational methods that separate out one aspect of multimodal communication phenomena will necessarily gloss over nuance. But, as noted, the trade-off is that the computational approach can help the researcher explore a large video corpus before drilling down for targeted, close reading. The computational tool results will also help situate the studied analysis of a few illustrations within the larger corpus of videos.
How to Scrape YouTube Transcripts
So how can YouTube video transcripts be scraped? To illustrate, I’m going to use an example from my research on racial reconciliation videos produced by non-profit organizations.
The first step is to collect a corpus of videos for study. A straightforward way to locate relevant videos is to keyword search for them directly in YouTube. But I prefer to keyword search through YouTube Data Tools online scraping tool because it will produce a spreadsheet list of the videos replete with metadata. Here is a sample of some of the metadata included in the spreadsheet.

Importantly, the spreadsheet contains a column titled “caption.” If the result of this column is “TRUE,” a transcript has already been automatically generated by Google’s speech recognition technology at the video creator’s request (or uploaded by the creator) and is available for download. If uploaded by the creator, the transcript may be 100% accurate. For those that are auto-generated, Google’s transcription technology has been rated as 72% accurate.
A. Scraping Video Transcripts
The video transcript contains no speaker segmentation and little punctuation, which is sufficient for text mining. You can access the transcript from the YouTube site directly (Click “Open Transcript” from the “. . .” to the right of the save button). You’d then need to cut and paste the transcript from its box on the right-hand of the screen into a spreadsheet or text document for future processing.
![]()
Or, you can use a free online transcript scraping tool like savesubs which will create a text file that you can convert into any text analysis format you need.
B. Creating Your Own Automated Transcripts
This is great for those videos that have been auto-transcribed, but what about those videos that are not already transcribed? There is open source software that can be used to automatically transcribe these types of videos, but not without some maneuvering.
- The first way is to play the YouTube video with the audio coming through your computer’s speakers. Have Google Docs open at the same time and enable the Google Docs dictation feature. This function works only in the Chrome browser.
- A second approach is to use Gentle, the free, open-source, English-language, automated transcription software licensed by MIT. This works only on Mac. An additional challenge here is that you must have a downloaded copy of the video (or a converted audio mp3 thereof) and YouTube’s terms of service forbids the downloading of its videos. You can request permission to download from the owner of the site.
- There are coding packages for automated speech recognition in R and Python. However, these packages also require upload of mp3 audio conversions of the video files.
Whether you scrape or automate, you’ll need to check your data for accuracy and format it in accordance with the analytical tools you’ll be using.
Analyzing the Data
Once you’ve gathered transcripts of the videos, and cleaned up your data, you can upload the text files to user-friendly computerized textual analysis software like Voyant or DARIAH’s Topic Explorer. For those who code, you can try topic-modeling packages created for R (e.g., topicmodels) or Python (e.g., topics).
![]()
As a micro example, I uploaded the transcripts of three racial reconciliation videos in Voyant. The top five words in this small corpus were: think, people, know, just, and like. Zeroing in on the uses of think with Voyant’s keywords in context tool, I’m seeing variations in how the term is used. Some discussions relate to the speaker’s beliefs about others (“They began to think they were superior”) while some represent appeals to the audience for affirmation (“You think that isn’t going to happen”). When viewed in Voyant, the Context tool will specify in which transcripts each use of think is found. The researcher can then more closely view videos according to their use of the term of interest.
I also uploaded 10 .txt transcript files into DARIAH’s Topic Explorer. This online topic modeling tool places document-topic distributions on a heat map that reveals which transcripts are associated with each topic found in the corpus. The topics are on the x-axis and the individual transcript files on the y.
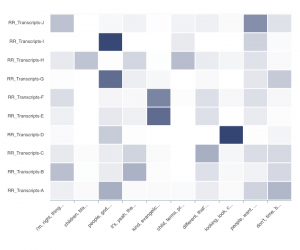
Here, the darker rectangles indicate a higher proportion of a topic in a particular document. Hovering over a rectangle reveals the exact proportion found in that document. Two topics I find interesting and worth more exploration are discussions about religion in racial reconciliation (“people, god, christ”) and perception (“looking, look, credibility”).
A detailed analysis of computational text analysis is not possible in this short post, but these illustrations show the exploratory value of computational text analysis of YouTube video transcripts.