By Jeff Antsen
Part 1: Data and Preprocessing
The LGBT rights movement has encountered a striking breadth in its victories and setbacks over the past decade. American society has not reached consensus on LGBT (Lesbian, Gay, Bisexual, and Transgender) rights and inclusion, and this rift is reflected in divergent media coverage of LGBT political issues. A burgeoning body of scholarship has examined how differences in attributional belief narratives about gay people might explain both evolution and polarization of public opinion about LGBT politics. I contribute to this research agenda by exploring the utility of computational content analysis methods, agnostically to identify the most differentiating and ideologically-laden words and features of LGBT news-media coverage.
My project proceeds through three phases. I discuss data collection and preprocessing below, and will discuss analysis in a future blog post.
Phase One: Raw Data Collection
First, I gathered news articles from the Proquest US News database, which offers historical and contemporary news stories in PDF and .txt formats from many high-circulation news sources. Many of these archives go back to the early 1980s or late 1970s. I collected all digitally available LGBT news coverage from several high circulation newspapers (The New York Times, The Philadelphia Inquirer, The Boston Globe, The Los Angeles Times, etc.) as well as several lower-circulation and more ideologically right-leaning sources (The Christian Science Monitor,The Las Vegas Review-Journal, The Saint Joseph News-Press).
LGB coverage was identified by using the following search:
pubid(*) AND ( noft(LGB*) OR noft(GLB*) OR noft(“gay m*”) OR noft(homosex*) OR noft(lesbia*))
This search identifies articles which use the stem of LGBT relevant terms in their title and/or abstract. The search term intentionally does not specifically include transgender-identifying terms, since the project is focused on narratives relating to sexuality, although LGB articles including discussion of trans* people or issues also were not excluded.
Phase Two: Text Preprocessing
The second phase of the project is text preprocessing – converting writing that is meaningful to the human reader (which includes punctuation, capitalization, and word endings that convey grammatical information like plurality or tense) into a form that is more meaningful for computational analysis.
The jargon for this is making sure each token(written instance) of a word identified by the computer as the same type(unique sequence of characters). Word tokens of various types often re-occur many times throughout a text. We typically want each instance of tokens that are the same in meaning – for example, each instance of the token “same” – to be identified as instances of the same type, here, the type ~same~. While the specifics of this may vary, the general intuition is that while each token in written language conveys meaning, many other aspects of a token – most commonly and importantly, its capitalization and the surrounding punctuation not separated from the word by whitespace, do not convey additional meaning. Therefore, we usually have a good theoretic reason to classify “Same”, “same.”, and “same,” all as tokens representing the single type ~same~. Preprocessing converts all of these slightly different tokens into lower case and punctuation-stripped “same” tokens, which computers will identify as of the shared correct type, ~same~.
Another aspect of this second phase, however is that sometimes combinations of tokens might convey a more specific – completely different – meaning than each token individually. For example, an instance of the token “bill” could refer to a legislative bill, or to the first name of former President Bill Clinton, or to the bill of a duck. Many “bill” tokens are present in my LGBT corpus. Some of these “bill”s refer to Bill Clinton, and others to legislative bills*. The contextof each “bill”; and in particular meaningful tokens that occur very close to it, help here. The distinction between Bill Clinton and legislative bills is quite important for my ability to understand the meaning conveyed by “bill” tokens in these texts, and both kinds of “bill” tokens are likely to occur even in the same news story. The same problem exists with the type ~clinton~. Both Bill and Hillary Clinton have historically been – and are currently – important political figures. However, it is quite useful for me to be able to differentiate when one or the other of these two Clintons are being discussed.
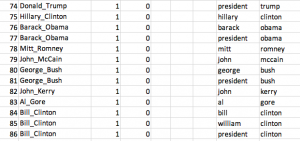
To handle this problem, I wrote a program using the R statistical language which identifies from pre-written dictionaries each instance the component words of many phrases, and collapses the two component words together into a single token, joined with an underscore between them. Rather than analyzing each token instance of the types ~bill~, ~hillary~, and ~clinton~ separately, I instead can run analysis using token counts of the much more useful and specific types ~bill_clinton~ and ~hillary_clinton~, and I can also more safely assume that most remaining tokens of “bill” refer to non-Clinton bills. I also recode other “clinton” tokens as ~bill_clinton~ or ~hillary_clinton~, depending on other preceding tokens like “mr”, “mrs”, or “president”. My next post will demonstrate how this pre-processing substantially improves results.
* While I do not believe any “bill” tokens in this corpus refer to the bills of ducks, this would also be neigh impossible to determine by only analyzing the corpus at the individual token level.
Hi,
I’m doing a similar project for my university dissertation. I’m examining whether news trends relating to “the troubles” conflict could predict the timing of conflict events during the conflict. Would love to see part two of this project as I’m a bit of an amatuer to R and text analysis.