By Alex Wermer-Colan
Their education at this point is heavily practical: how to run machines, how to get along without machines.
– Joanna Russ, The Female Man (1975)
This spring at Temple University’s Digital Scholarship Center, I ran a workshop series where students, librarians and faculty experimented on a shared data-set to learn user-friendly modes of text mining. There seemed no more fitting corpus for beginners to learn to read books with machines than the DSC’s digitized batch of New Wave sci-fi literature (for more on our digitization project, see this blog post from last fall).
The workshop series explored over five sessions how to prototype a digital project, from curating the datasets and hypothesizing points of inquiry to establishing best practices for analysis and modeling the corpus to clarify and complicate our research questions. We weren’t looking for hard and fast results; instead, we hoped to discover what critical questions could be provoked by visualizing textual data with such accessible tools as Voyant.
I’ve found that text mining can be hard to teach, and learn, in traditional workshop models. I hoped a collaborative process would make it fun to dig into the granular details as we developed the habit of using digital tools in our research. Along the way, we would track our workflow and record our results, working together to build a wider knowledge base for future research.
To begin the workshop series, I asked participants to imagine a decade into the future, when we’ll look back at contemporary digital tool-kits in the same way we look back today at the transistor radio. A radio, actually, offers a useful metaphor for Voyant: to operate the machine, you twist knobs and you toggle buttons, adjusting the frequency and volume of textual transmissions.
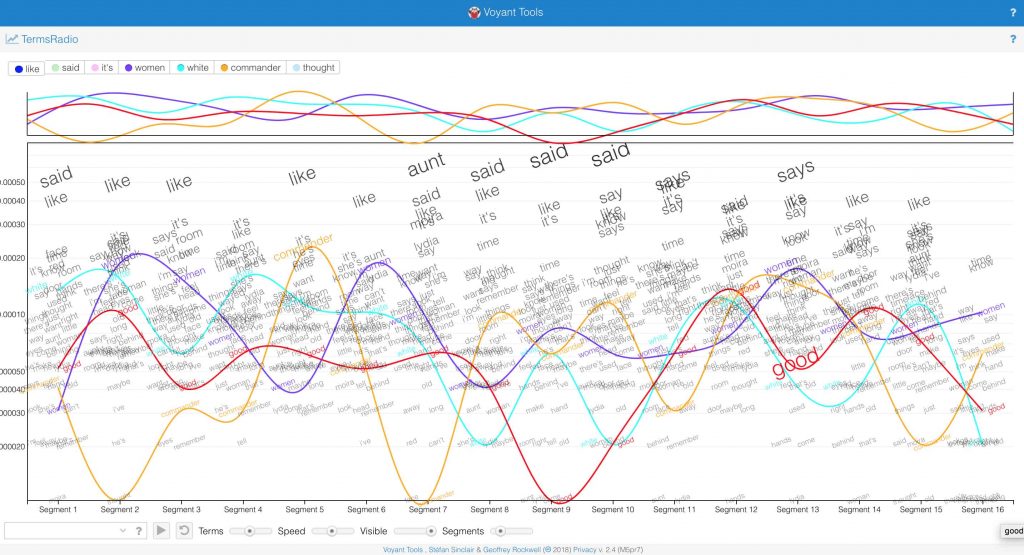
There’s even a tool, TermsRadio, that simulates an analog interface to track trends in word usage across texts. This is what Margaret Atwood’s The Handmaid’s Tale (1985) looks like with “white,” “woman,” “thought,” and “commander” highlighted:
Having familiarized ourselves with the program, and reviewed best practices for tracking our stop-words, we worked in teams over five sessions, filling out spreadsheets on subsets of our corpus. In this way, we accumulated information on a wide range of textual qualities, from metadata on the books’ publication to the novels’ vocabulary densities (the ratio of total word count to unique words in the corpus).
In the wake of Lauren Klein’s “Distant Reading After Moretti,” it seemed apt to start with a microanalysis of Atwood’s The Handmaid’s Tale. We then zoomed out, comparing Atwood’s dystopian novel with other feminist sci-fi novels by Ursula Le Guin, Joanna Russ and Octavia Butler. In subsequent sessions, building towards a macro-analysis of the genre, we traced trends across the New Wave over a thirty year period. Finally, we compared our New Wave corpus with Project Gutenberg’s bookshelf of over 800 sci-fi texts from previous eras. Along the way, the workshop accumulated word clouds, trend graphs, concordance lists, collocation grids, correlation networks, topic models, and scatterplots.
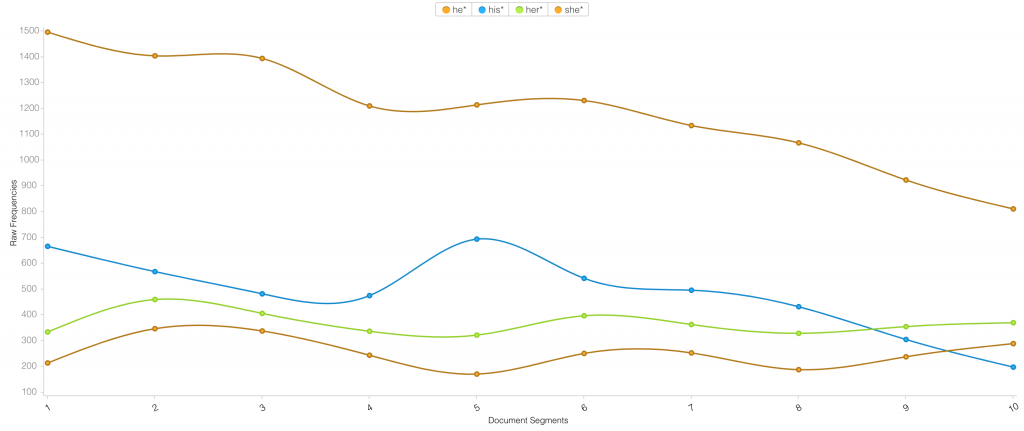
As one example, see below a graph of gendered pronouns in Samuel Delany’s Dhalgren (1975). It seems fitting that there’s a subtle decline in male pronouns over the duration of Delany’s epic novel:
Introductory Text Mining of New Wave Sci-Fi
I begin a sentence lover. It’s at the level of the sentence you’re more likely to find me, as a writer. Now I’m interested in the larger structures sentences can fit and generate. Still, for me, writing begins as an excuse to put together certain sorts of particularly satisfying sentences.
– Samuel Delany, Interview with Lance Olsen, 1989
For a lover of sentences, sci-fi and fantasy open new vistas where, in a single clause, incongruous meanings and worlds can appear juxtaposed within a semi-rational framework. We spent much of our time investigating this estrangement effect through the use of Voyant’s versatile network analysis tool, “Links.”
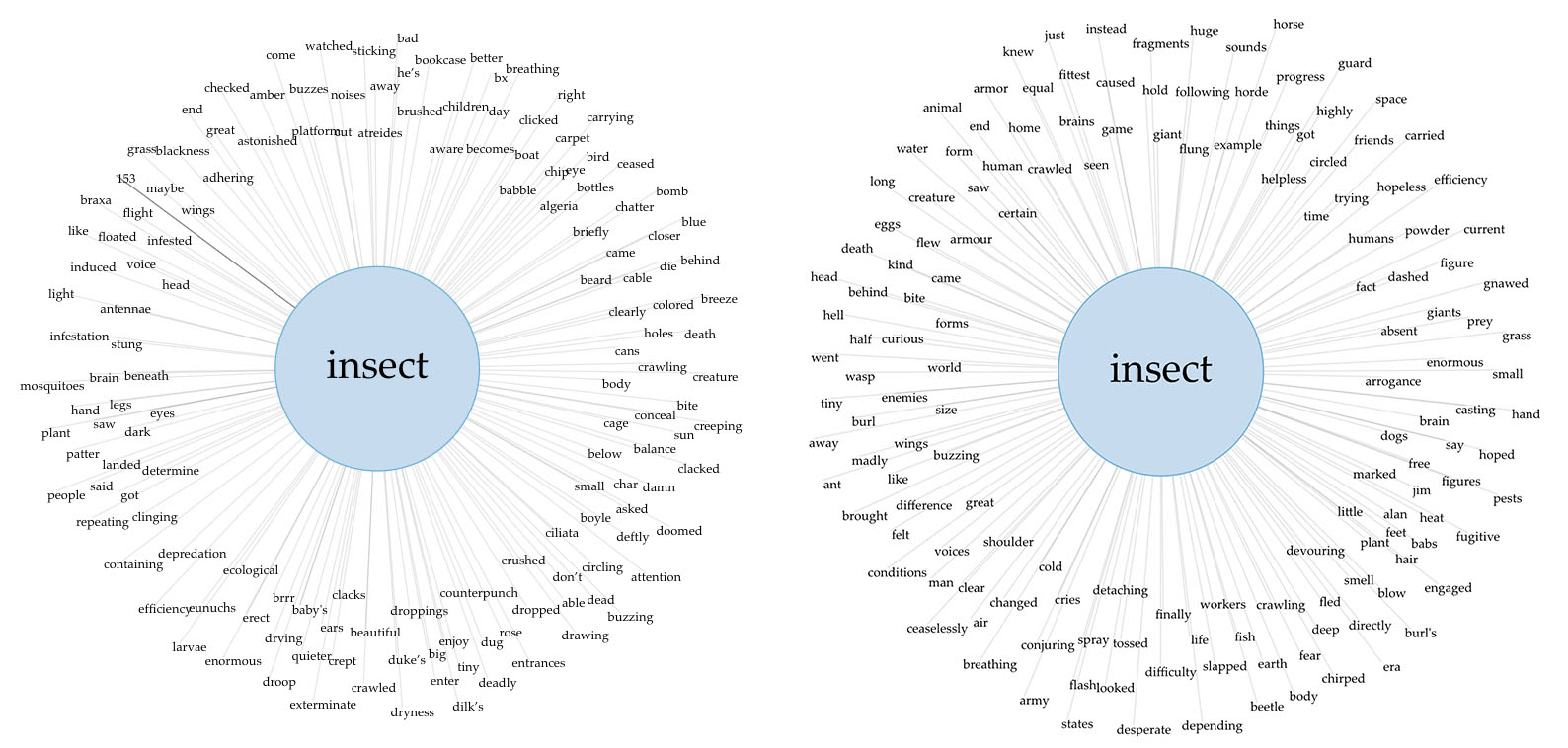
Using the “centralize” option, we created a centralized, hierarchal network map of a single word in a text. Below I’ve juxtaposed the word “insect” as it collocates in the New Wave corpus (on the left) and Gutenberg’s sci-fi bookshelf (on the right):
By augmenting the “contextualization” parameters, we modeled a larger cluster of key words. After sculpting the visualization, we created distributed networks of words as they appear across our New Wave corpus and Gutenberg’s set of sci-fi texts. See below one such visualization from our New Wave corpus, organized around themes of viral contagion.
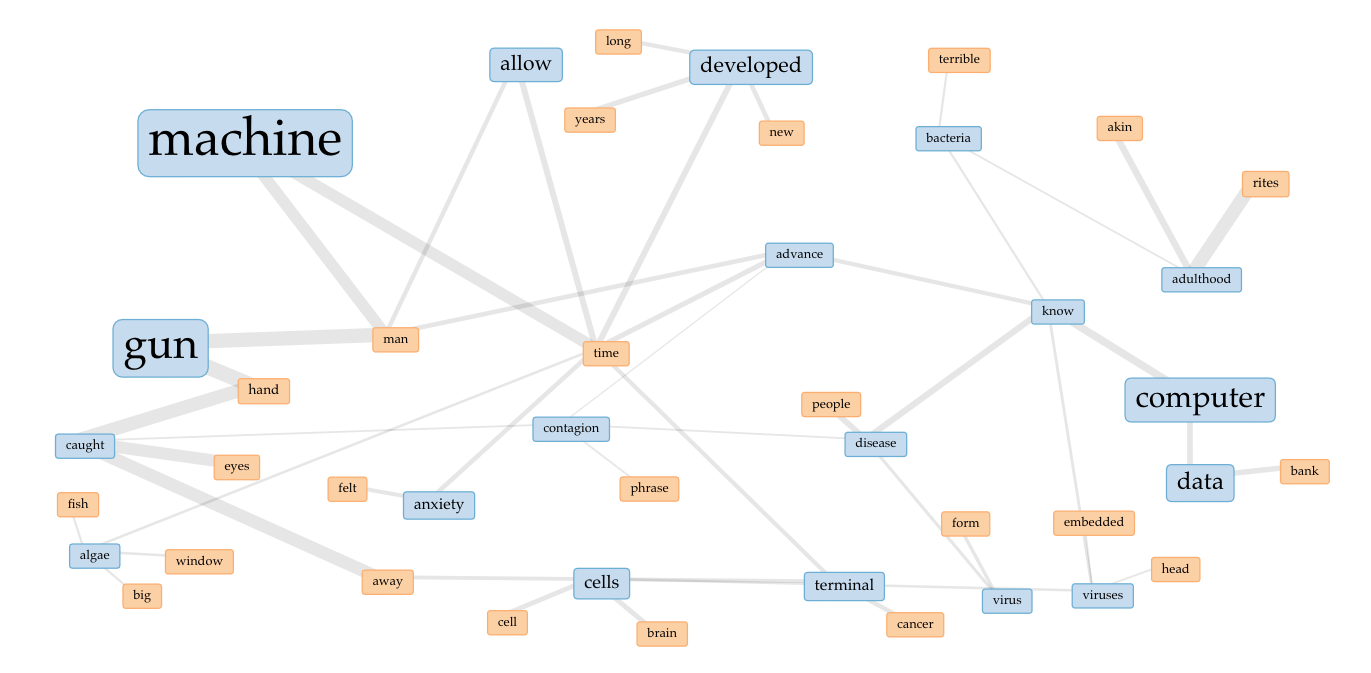
Besides a wide-array of useful visualizations, our data crunching identified, for instance, the most lexically dense and diverse texts, such as those novels by Joanna Russ and Samuel Delany. Our broader distant reading of the sci-fi genre sketched out how computational, data-based analysis can challenge conventional notions of periodicity. The modernist styles associated with the New Wave may have been officially identified in 1962, but I suspect its antecedents can be found in the 1950s, with such writers as Theodore Sturgeon, Alfred Bester, and William S. Burroughs.
Just as an in-depth knowledge of the literary field would be necessary for a complex research project, this workshop also clarified for participants the limits of entry-level textual analysis tools. Word frequency analyses, even as high-octane a method as topic modeling, can only look at texts from certain angles (for an easy to use topic modeling tool, see Scott Enderle’s tool here). To study the shifting meaning of words in the history of science fiction, we agreed it would be necessary to use more advanced techniques like word2vec.
In this sense, our collaborative experiments demonstrated the necessity of a multi-faceted, iterative approach involving both “analog” and “digital” methods of close and distant reading. We concluded the workshop by discussing two directions that beginners in text analysis could go next, coding and encoding: coding to conduct more complex text analysis using multi-dimensional vectors and machine learning, and encoding, to create more supple data sets for computational analysis.
Future Inquiries into Sci-Fi Lit
The marriage of reason and nightmare which has dominated the 20th century has given birth to an ever more ambiguous world. Across the communications landscape move the specters of sinister technologies and the dreams that money can buy. Thermonuclear weapons systems and soft drink commercials coexist in an overlit realm ruled by advertising and pseudoevents, science and pornography.
– J.G. Ballard, “Introduction” to Crash, 1974
New Wave sci-fi marks the period when minority perspectives erupted into a genre previously produced by and for a white, male, heteronormative community. One of our earliest inquiries into the New Wave corpus hinged upon words pertaining to skin color. We wanted to see, for instance, the disparity in how race is constructed and critiqued in such feminist novels as Ursula Le Guin’s Left Hand of Darkness (1969), Joanna Russ’s The Female Man (1975), Octavia Butler’s Mind of My Mind (1977), and Atwood’s The Handmaid’s Tale (1985). Studying the historical shift in sci-fi representations of race (see recent work by Richard Jean So) illustrates why it is vital for us to enable computational analysis on copyrighted material. At least, that is, if we hope to study the wide array of texts written since white hegemony over Western literary production waned.
As a sample, here’s a Bubblelines visualization we created with these classic works of feminist sci-fi:
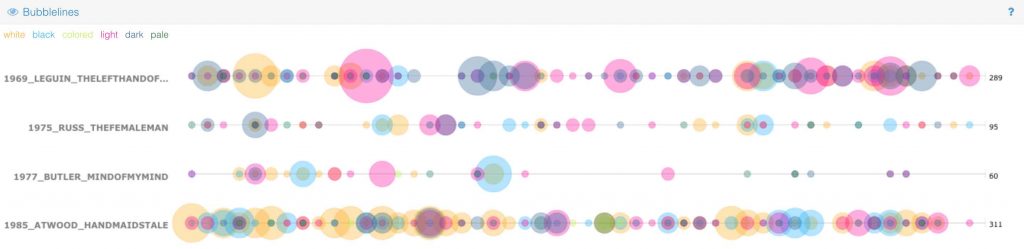
Analyses of words pertaining to ethnicity and race proved useful for engaging the workshop audience with the ways even elementary computational analysis can unpack freighted political topics. But the best takeaway for me was the seriously meta research question it opened up: in what ways does science fiction offer the premiere genre where the possibility of machine interpretation of literature becomes conceivable and problematized?
In other words, how can we use machines to analyze how twentieth-century sci-fi writers imagined the development of machine learning? In particular, which writers anticipated contemporary critiques, articulated most famously in Safiya Noble’s Algorithms of Oppression (2018), of machine learning and artificial intelligence as inevitably biased by all too human prejudices?
Finally, this workshop series, and collaborative research in the DSC more generally, helped us think through the variety of ways a book can be understood as “data.” This includes such exciting developments in digital literary studies as geo-spatial mapping of fantastical spaces. We’ve been most fascinated by the genre’s beautiful cover art, and the possible ways we can analyze it at a pivotal turning point in the evolution of the mass market book industry.

Since the workshop, I’ve been working in the DSC with James Kopaczewski and Jordan Hample to experiment with machine learning algorithms to conduct image analysis on the sci-fi book covers. After discovering a treasure trove of one hundred thousand sci-fi book covers on the Internet Speculative Fiction Database, we are experimenting with Yale DH Lab’s shockingly easy-to-use Pix-Plot to cluster together and project in three dimensional space the wide range of cover art designs.
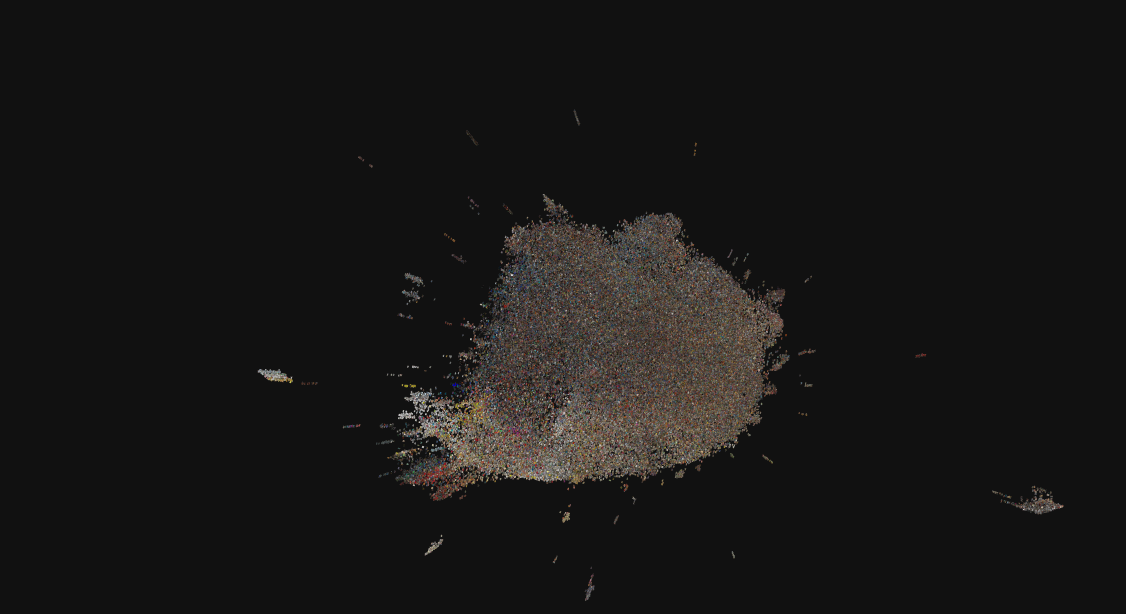
The featured image to this blogpost took a Star Wars-esque vantage point. Above you can see a head-on view of the layered array of book covers. At the end of this blogpost, see how one hundred thousand sci-fi covers look from far away, like a supernova in the void of outer space.
Stay tuned for future postings exploring advanced modes of textual and image analysis using our growing sci-fi corpus. I’ll overview along the way recent trends in digital scholarship on science fiction literature (see two exemplary essays here and here). We’ll also be posting updates on the progress of our digitization project by fall semester.
Over the summer, we’re lined up to digitize a wide-range of post-WWII sci-fi, from best selling novels to short-story anthologies, like The Best Science Fiction of the Year series. We’ve dug up a full run of Analog magazine from 1953-1979. To provide a rounded perspective, we’ve also selected for the chopping block a diverse set of esoteric and forgotten novels that remain out of print and un-digitized in any form.