By Luling Huang
“The primary problem is volume: there are simply too many political texts” (Grimmer & Stewart, 2013, p. 267).
My 43,000+ posts do not look terrible at all in terms of volume, compared with Big Data studies. For example, Colleoni, Rozz, and Arvidsson (2014) classified political orientation of Twitter users based on 467 million tweets. But since one of my goals is to learn and use automated methods for quantitative content analysis, I started to explore some literature and hands-on blog posts on these techniques.
I found Grimmer and Stewart’s (2013) piece helpful to get an overview of the field.
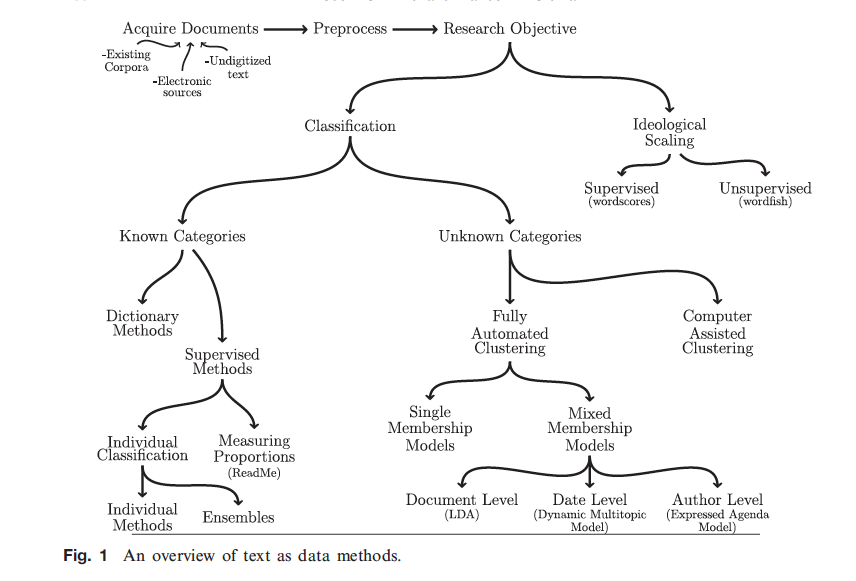
(Figure from Grimmer & Stewart, 2013, p. 268)
From these methods, supervised machine learning is more appropriate to use when classification categories can be specified before analysis. Unsupervised methods do not presume any predetermined categories, but cluster documents with common words. Thus, unsupervised methods impose difficulties in interpreting clusters afterwards (Burscher et al., 2015). Supervised methods are also superior to dictionary-based methods. Interpreting words is often contextual, which dictionary methods often fail to take into account. Also, dictionary methods are difficult to validate, especially when a dictionary is developed outside the data under analysis (Grimmer & Stewart, 2013).
What is the logic of supervised learning? It starts from human coding of a representative sample of data (the training set). A classifier is trained to find the relationship between category and text feature (e.g., a unigram document-term matrix, see Christian S. Perone’s (2011) excellent demonstration if you’re interested in the terminology). After validating a group of classifiers within the training set by checking machine classification against human coding, the best performing classifier is used to classify the remaining portion of data.
Therefore, supervised machine learning is a good way to combine automation and human work. It is certainly less laborious than manual coding, which is the main drive for using automated methods. And the method also has human coding as a check for its validation.
Regarding supervised approach’s application in political analysis, Colleoni et al. (2014) used supervised methods to infer political orientation of Twitter users from tweet contents. Their classifier achieved an accuracy of 79% (10-fold cross-validation) in the training set of the Democratic/Republican coding (2014, p. 324). Burscher et al. (2015) used supervised learning to classify political issue topics in news articles. One focus in this piece was conducting classifier’s validation across contexts. A notable validation result was that classification accuracy decreased strongly when the classifier predicted unknown articles from a different time period or non news articles (2015, p. 128). This finding indicates the importance of getting a representative sample for training sets.
So, how to actually DO it? The most importance starting point would be human reading: to get a better sense of what the data looks like. For example, what would be a reasonable set of predetermined categories to investigate our research questions? Then, constructing a code book for manual coding would be the next step. And all traditional procedures in content analysis (e.g., coder training, checking reliability, revising code book if necessary) follow. The automated part comes after, including text preprocessing, feature extraction, determining algorithms for training classifiers, validation, classifying remaining data, etc. These hands-on blog posts are good places to start with: Wang’s (2016) post on running supervised Sentiment Analysis in R, Bromberg’s (2013) post on how to proceed in R as a beginner, and Perone’s (2011) post on key concepts’ explanation and having fun in python.
I’ll end this post with Grimmer and Stewart’s (2013) second principle of automated content analysis (maybe the most important one): “Quantitative methods augment humans, not replace them” (p. 270).
References
Bromberg, A. (January 5, 2013). First shot: Sentiment Analysis in R. [Blog]. Retrieved from http://andybromberg.com/sentiment-analysis/
Burscher, B., Vliegenthart, R., & De Vreese, C. H. (2015). Using Supervised Machine Learning to Code Policy Issues Can Classifiers Generalize across Contexts?. The ANNALS of the American Academy of Political and Social Science, 659, 122-131.
Colleoni, E., Rozza, A., & Arvidsson, A. (2014). Echo chamber or public sphere? Predicting political orientation and measuring political homophily in Twitter using big data. Journal of Communication, 64, 317-332.
Grimmer, J., & Stewart, B. M. (2013). Text as data: The promise and pitfalls of automatic content analysis methods for political texts. Political Analysis, 21, 267-297.
Perone, C. S. (September 18, 2011). Machine learning :: Text feature extraction (tf-idf) – Part I. [Blog]. Retrieved from: http://blog.christianperone.com/2011/09/machine-learning-text-feature-extraction-tf-idf-part-i/
Wang, C. (January 10, 2016). Sentiment analysis with machine learning in R. [Blog]. Retrieved from https://www.r-bloggers.com/sentiment-analysis-with-machine-learning-in-r/
Despite widespread recognition that aggregated summary statistics on international conflict and cooperation miss most of the complex interactions among nations, the vast majority of scholars continue to employ annual, quarterly, or occasionally monthly observations. Daily events data, coded from some of the huge volume of news stories produced by journalists, have not been used much for the last two decades. We offer some reason to change this practice, which we feel should lead to considerably increased use of these data. We address advances in event categorization schemes and software programs that automatically produce data by “reading” news stories without human coders. We design a method that makes it feasible for the first time to evaluate these programs when they are applied in areas with the particular characteristics of international conflict and cooperation data, namely event categories with highly unequal prevalences, and where rare events (such as highly conflictual actions) are of special interest. We use this rare events design to evaluate one existing program, and find it to be as good as trained human coders, but obviously far less expensive to use. For large scale data collections, the program dominates human coding. Our new evaluative method should be of use in international relations, as well as more generally in the field of computational linguistics, for evaluating other automated information extraction tools. We believe that the data created by programs similar to the one we evaluated should see dramatically increased use in international relations research. To facilitate this process, we are releasing with this article data on 4.3 million international events, covering the entire world for the last decade.