
By Jillian Benedict
Before I can start using R to look for patterns in Jon Krakauer’s body of work, I need to take the written text and turn it into a form that allows me to work with the text in R. For the sake of my project, I have decided to turn the text of each into a plain text file. Unlike html or any other markup computer language, plain text is exactly what it sounds like. It is the most bare-bones version of a text. This allows me to focus on what Krakauer has written as opposed to getting caught up in any special formatting or layouts that may have been chosen to add aesthetic interest to the print version of the book.
Taking a print text and turning it into a plain text file is a process, but an important process nonetheless. The first step, of course, is to scan Krakauer’s novels onto the computer as a PDF so I can work with the text freely and without concern for infringing upon any copyright laws that cover digital issues like those found on Google Books (assuming the whole text of a book is available on Google Books). Scanning each book from cover to cover is time consuming, but it is time well spent and provides me all of the information pertinent to the publication of each book in a digital format which may make it easier to access later. Once I have a book scanned, I send the PDF through OCR software. What is OCR? Well, OCR otherwise known as “optical character recognition…is a system of converting scanned printed/handwritten image files into its machine readable text format” (Basu). Once the files have been run through OCR software, I can turn them into a word document, which will allow me to remove any unnecessary information from the text.
The OCR software I use is ABBYY FineReader, which can allows you to clean up the scanned files if necessary so the computer can read them better. It was a little difficult to figure out, but vital once I understood what I was doing. I know what you are thinking. If the computer can read the text using Abby Fine Reader, why does the file need to become a word document? Unfortunately, just because a computer can recognize the characters in the document doesn’t mean the computer always reads those characters correctly. Let’s look at an example.
As you can see in the photograph below of Part II in Under The Banner of Heaven (I chose to make it into a PNG file using the Snipping Tool instead of taking a screenshot) ABBYY FineReader “reads” the scanned image on the left, which says “Part II,” but it does not read it correctly. On the right side of the image is a close-up of what this page would look like on the word document created out of the OCR software. It says “Parl ll.” The OCR software did not understand that the letter “t” in “Part” is a “t”. It read it as an “l”. It is just a small but important example of some of inconsistencies in OCR software. Even though the example is just a header for a new section, for the sake of accurate text analysis the word document needs to be as close to the printed text as possible.
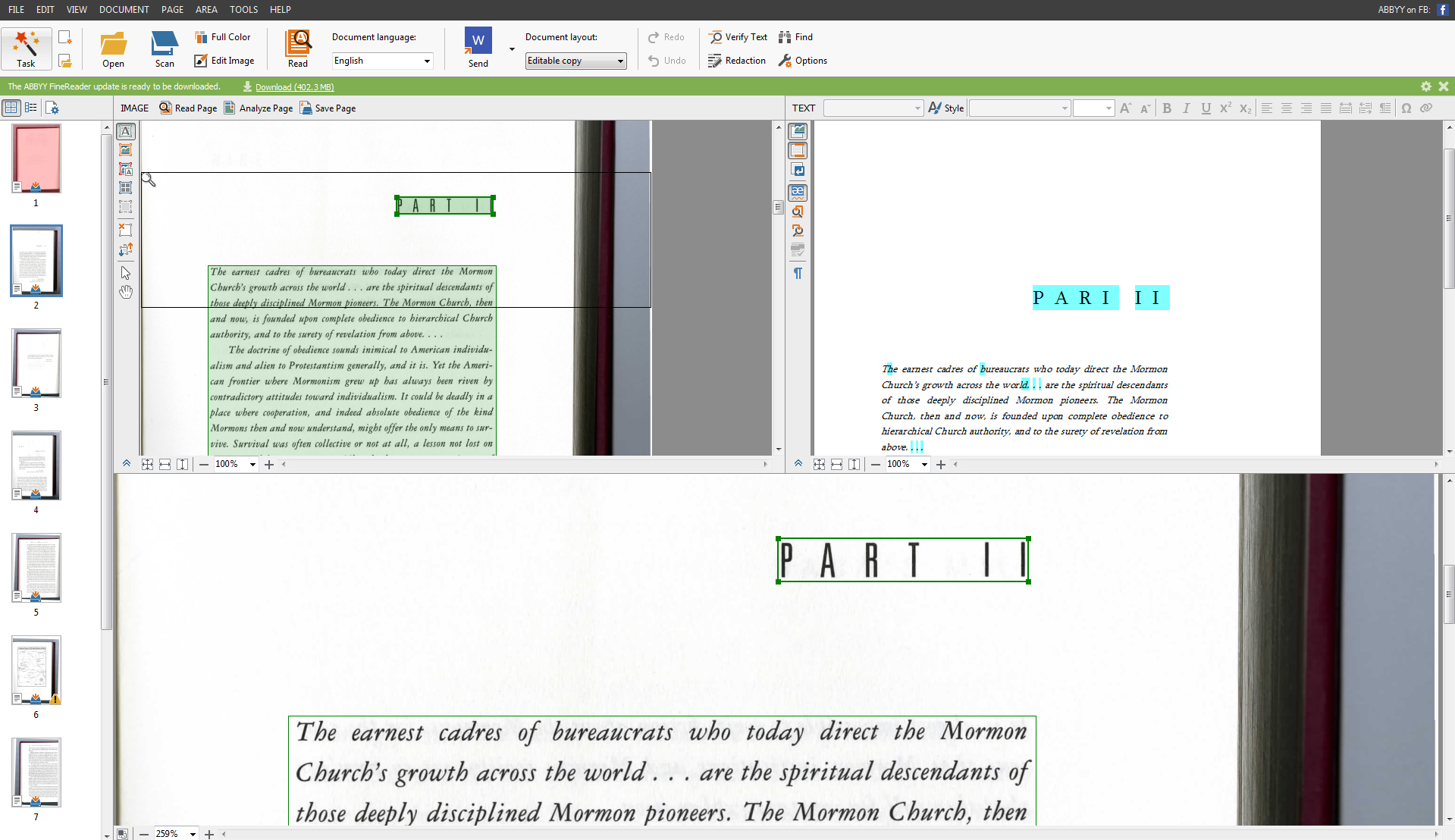
This is a tedious part of the process, but creating an accurate and machine readable text is crucial to the development of this project. Even though I am still unsure about what I will find once I can play with the text itself, I am one step closer to finding out what analyzing all of these novels will reveal about the change in an author’s style over time.
Basu, Saikat. “Top 5 Free OCR Softwear Tools To Convert Images Into Text.” Makeuseof.com,
http://www.makeuseof.com/tag/top-5-free-ocr-software-tools-to-convert-your-images-into
text-nb/. Accessed 1 Nov. 2016.