By Ping Feng
In Part I, I discussed the Cinemetrics project, a prominent database with film editing statistics. Though it is still largely based on manual collaboration, its decent amount and richness of data have been utilized by many scholars to either conduct further cinematic analysis or theorize their methodologies. For example, Mike Baxter has worked on papers such as Evolution in Hollywood editing patterns? and Cutting patterns in D.W.Griffith’s silent feature films by using descriptive data and R code (Baxter, 2012). More of his theoretical principle and data analysis methodology can be found here .
Another example is Nick Rederfern’s work. He maintains a blog – Research Into Film – where some of his film studies are presented by using quantitative approach theorized by Cinemetrics.
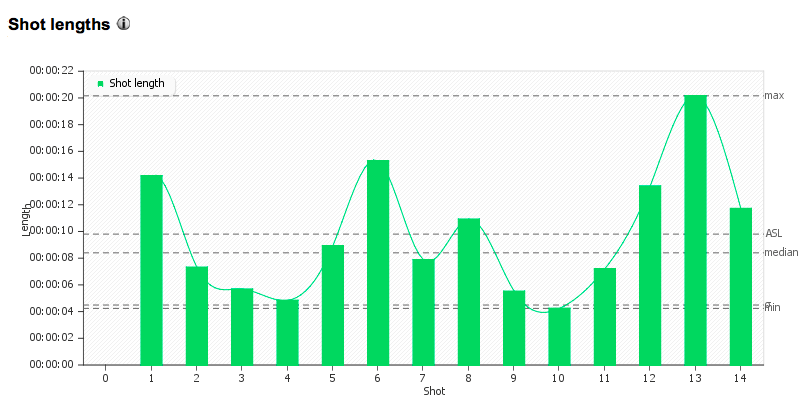
Shot Logger is another open source database assembled the Cinemetrics but at a smaller scale. It provides visual style analysis and a database with editing statistics for 928 instances of 246 films and TV programs and a gallery of 282,157 frames captured (Jeremy Butler, data updated till April 8, 2015). The drawback for this site is that the data, such as Average Short Length, Median Short Length, is mainly presented numerically, not graphically.
However, in addition to the sheer volume of the digital video available in competing users’ attention, the unique nature of digital video with both temporal and spatial elements also requires a more automatic way to collect, retrieve, and analyze the data. For instance, in order to collect the number of cuts or the appearance of certain face in a one-hour long video for analysis manually, it will be both time-consuming and expensive to transit and stream the giant size of video for at least one hour or so. Therefore, the need for efficient analyzing and retrieving video images has called for an automatic way of metadata extraction and indexing.
One project, completed by undergraduate Fredric Brodbeck, is also called “Cinemetrics”, but with a different concept. He developed an precise tool to “automatically” extract, process, and visualize movie data. A video demo of his project can be found here, and his code is available here.
Some organizations have already developed tools or algorithms to automatically extract, analyze, and visualize the metadata of digital video editing statistics or visual images. For example,
- Lignes de Temps features video-flow annotation and cut-detection tool, but it is all in French, thus less popular
- Edit 2000 is an excellent tool and platform to upload edited video files and obtain editing decision lists automatically with both numeric summary and visual display.
- Software Studies Initiative is a software-based platform focusing on cultural analytics and discovering cultural patterns by analyzing the big data of digital video and visual images. Though it has been more focused on visual image analysis, some of the prominent projects include: Visualize Instagram: Selfies, Cities and Protests, On Broadway-a New Interactive Urban Data Visualization from Selfiecity, Political Video Ads, Cinema Histories-Patterns across 1100 Feature Film, 1900-2008.
Further, there are other exciting projects that work to extract content related metadata automatically:
- Open Video Digital Library by Marchionini and Geisler (2002), University of North Carolina at Chapel Hill. In this system, key frames were first extracted using MERIT software (University of Maryland).
- Informedia Digital Video Library by Carnegie Mellon University has integrated speech, natural language process technologies to automatically recognize speech in video soundtrack and transcribe it into text information in alignment with linear video segments and index to create “video paragraphs” or “video skimming” for efficient retrieval.
- IBM’s Cue Video summarizes a video and extracts key frames. It acquires spoken documents from video via speech recognition.
- IBM Research TRECVID-2004 Video Retrieval System is content-based automatic retrieval project focusing on four tasks of shot boundary detection, high-level feature detection, story segmentation, and search by using IBM Cue Video the team has previously developed.
- Digital Video Multimedia Group at Columbia has been engaged in multi-media content analysis, data extraction from images, videos with the efforts to build large-scale search engines, machine leaning and recognition system for automatic index and retrieval of the data.
- The Fischlar System at Dublin City University(1999) is an digital library with several hundred hours of video content, operating via TREC Video Retrieval track. It can detect and removes the advertisement from the video shots and analyzes the remaining content by spoken dialogue indexing, speech/music, discrimination, face detection, anchorperson detection, shot clustering, and shot length cue, all of which are implemented based on Support Vector Machine algorithm. Finally, it applies the story-segment program to combine several shots into story segment and save the result in the database.