
By Ping Feng
Hello everyone, my name is Ping Feng. I’m currently a graduate student in School of Media and Communication at Temple University, major in Media Studies and Production. I’m very excited to join the Digital Scholarship program in 2015 and looking forward to getting the most out of it. Last year, some of the Digital Scholarship Graduate Students explored the application of textual analysis tools and methodology in digital humanity studies. This has inspired me to further explore tools and methodologies for non-textual analysis, particularly the digital video and image analysis, since the volume of digital videos has grown dramatically. This can be seen, for instance, in the rapid development of information technology and the subsequent demand for more efficient retrieval and analysis on digital video content.
In reviewing existing studies in digital video analysis technologies and projects, I argue that digital video analysis can be divided into two approaches, depending on the types of metadata extraction and research goals. The first is to extract the “hard data”, which includes some production related data such as production time, location, run time, number of frames and bits, number of cuts and average shot length and so on. This kind of data sometimes even comes with the production process and has lower technology bundles. The purpose is usually to compare and analyze the editing styles differences over time or over different ownership.
The second approach is to extract “soft data”, which deals with the content of the video, such as key frames extraction, major color tone summarization, speech recognition and transcription into text, and even a combination of all of these to provide a semantic description of the video content. This approach usually has higher technological bundles and usually serves the purpose of narrative style analysis. These two types of metadata, though with different emphases, both serve the purpose of better navigation and efficient retrieval of the data so that users could jump directly and precisely to the video clips in which they are interested. Both of these types of data could be achieved manually, while the ultimate goal is to do it automatically.
Besides the technological bundles, many people have argued theoretically about the feasibility of content analyses of film or video clips. They view it as “a form of arts” and therefore “has no room for numbers and measurement”, as mentioned by Bosse & Tsivian, the founder of Cinemetrics.lv. However, video analysis has much in common with textual data analysis: just like we count the frequency of certain keywords and further analyze the writing styles in text analysis, we also count the number of cuts, Arithmetical Length of Shots (ALS) to evaluate the average timing, pace as well as editing styles of the film or video.
One of the prominent projects has been done is the Cinemetrics by Bosse and Tsivian from University of Chicago. The project aims to create a free open source of film editing data accessible online based on common collaboration. Until 2011, there had been approximately 6,900 film editing data contributed by almost 6,000 individuals since its establishment four years ago.
[The Interface of Cinemetrics Film Editing Data Counting Tools]
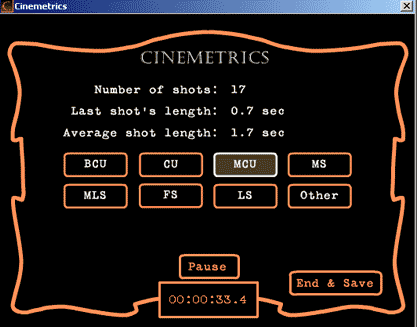
Note: This is the classic version of the tool (download here, requires flash player plugin installed in browser). It is like a stopwatch that records the times at which you click your mouse or keyboard button. You are presented with a simple interface which allows you to push buttons as shots on the movie player switch. The software must be run simultaneously with the user watching the movie. An advanced frame accurate beta version tool can be accessed here ).
[A Sample of A Film Editing Data Display]

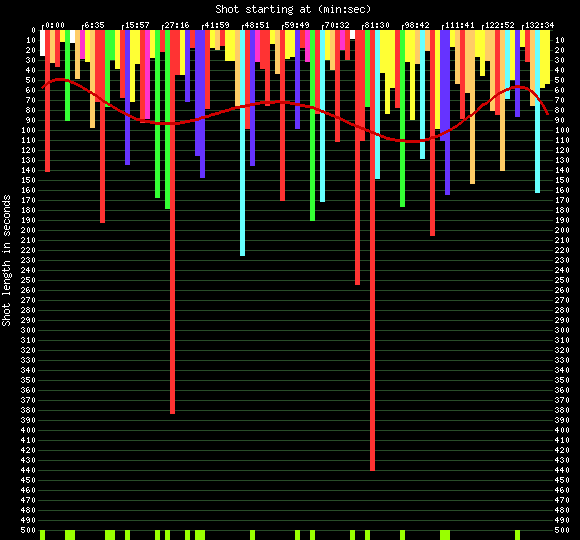
Note: the red curve shows a general editing swing; the shot length has been color coded so that it is easier to eye-bowl the distribution of the shots with different lengths for further analyses.
Although this project has inspired many other scholars in utilizing its data and tools for cinematic studies and establishing resemble database, which I will explain further in Part II, the major issue of this project is that it is still based on manual extraction of data, which is not a long-term solution in responding to the request of fast retrieval and analysis of soared volume of digital video data, and it only focuses on collecting editing decision related metadata, which is quite limited.