
By Mohaiminul Islam
Introduction
In the last couple of decades, Machine Learning (ML) has revolutionized the field of data-driven learning. For my Scholars Studio digital research project, I used ML as a tool for accelerating topology optimization calculations. In my last blogpost, I discussed topology optimization for improving machine fabrication methods like 3d printing, a technique for developing optimal designs with minimal a priori decisions. Because the optimization process is iterative in nature and can be slow to arrive at optimal results, I am using ML to accelerate the optimization process, thereby facilitating the rapid manufacturing of optimized parts for cars and other heavy machinery.
ML can be used in several ways such as image processing, data regression, data classification, language processing, and so on. My project requires the use of computer vision, and, in particular, a process known as image segmentation, where an image is divided into multiple segments or regions, each of which corresponds to a different object or part of the image. For example, taking something like satellite imagery of a city, where one needs to identify buildings, roads, and vegetation, the ML algorithm will go over the image and segment parts of the interested areas which enables the urban planners and policymakers to make an informed decision in planning a city’s infrastructure.
In recent times, CNN (Convolutional Neural Network) based architectures have enjoyed unprecedented success in image segmentation. In this project, I am using CNN-based architecture for image segmentation. Among several architectures to compare with, in this project, I compare U-net, ResUnet, and GAN (Generative Adversarial Network). My goal was to use ML as a means to get an optimized structure in an instant (i.e. for the last example ML algorithm predicts 4000 times faster compared to the traditional optimization algorithm). Usually, topology optimization algorithms use iterative methods to get an optimized structure, requiring hundreds of iterations. If ML is properly trained, however, these iterations are not necessary to generate the target structure.
ML architectures for image segmentation
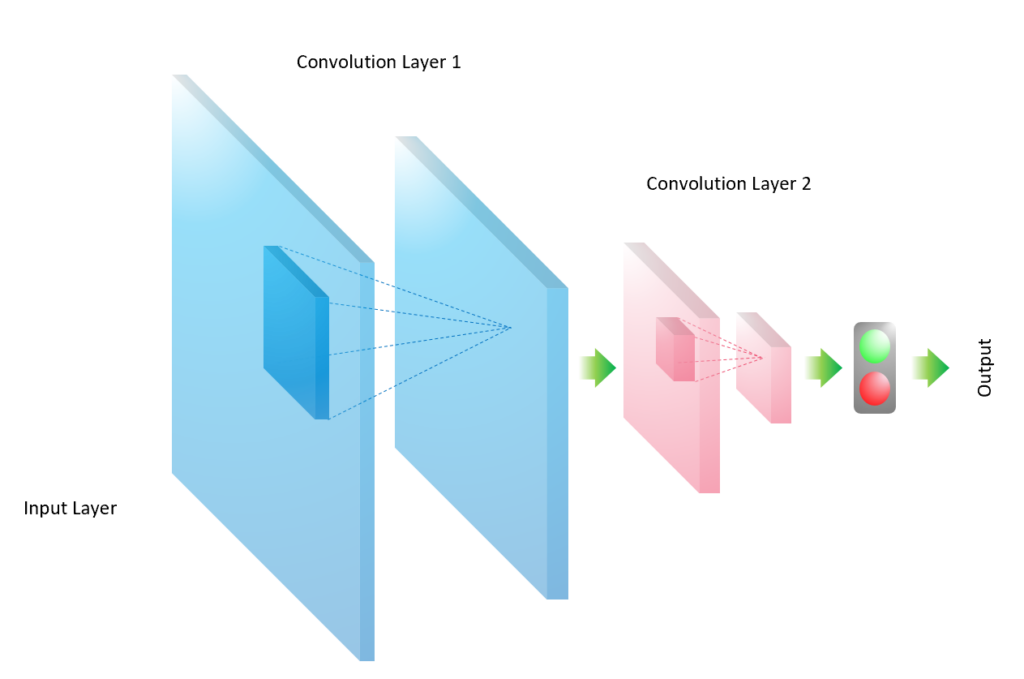
The convolutional neural network (CNN) is like the ANN (Artificial Neural Network), but it is used especially for image processing due to its ability to extract abstract features from an image or a matrix via convolutional operations. As illustrated in Figure 1, the convolution layer is a core building block of the CNN, which is responsible for the dimensional reduction and feature extraction. For instance, the CNN in Figure 1 has two convolution layers, both starting from an image and yielding an abstracted feature image with reduced dimensions. The process to reduce the dimension of an image is called convolution.
Such convolutional operations may be done multiple times in a CNN; and between these convolution layers, normalization and resizing can be done to prepare data and improve the performance of the CNN. In addition, the performance of CNN is also influenced by the choice of the convolutional filter and its striding velocity. Finally, the loss function is evaluated and minimized by adjusting the weights in the CNN.
One of the major applications of CNN is semantic segmentation, a process that classifies pixels in an image to specific categories (e.g., roads, pedestrians, and vehicles). More advanced architecture such as Unet and ResUnet are derived from CNN. I implemented the ML model in Python using TensorFlow and Keras. Keras is an open-source high-level API built for TensorFlow. Because it was designed for humans, not machines, and it is relatively intuitive and user-friendly.
Unet and ResUnet
For this project, I used ResUnet for image segmentation. In this section, I try to explain why I choose ResUnet as my choice for image segmentation. As Unet and ResUnet are very similar encoder-decoder based architectures. In ResUnet there is an additional bridge component connecting the encoder and decoder. Each part has one or more residual units that are a composition of multiple mathematical operations. The network is trained by optimizing the parameters and weights to best predict the target.
The difference between Unet and ResUnet is in their skip connections. A unique feature of ResUnet is that it has two types of skip connections that allow efficient training of deep networks by facilitating the flow of information without degradation. On the one hand, the skip connection within a residual unit (also called the short skip connection; represented by the red dashed arrow in Figure 2(b)) skips a few layers and connects directly to the output of the unit. The short skip connection enables each block to avoid overfitting and vanishing gradient. In Unet only the long skip connections are present.
Due to highly efficient learning enabled by the two types of skip connections, the number of samples needed to train the NN is drastically reduced. Usually, Unet and ResUnet achieve similar performance, however, Unet having only the long skip connections usually require a larger dataset to achieve similar performance. A larger dataset means a computationally more expensive dataset. This is the main reason I chose ResUnet for image segmentation.
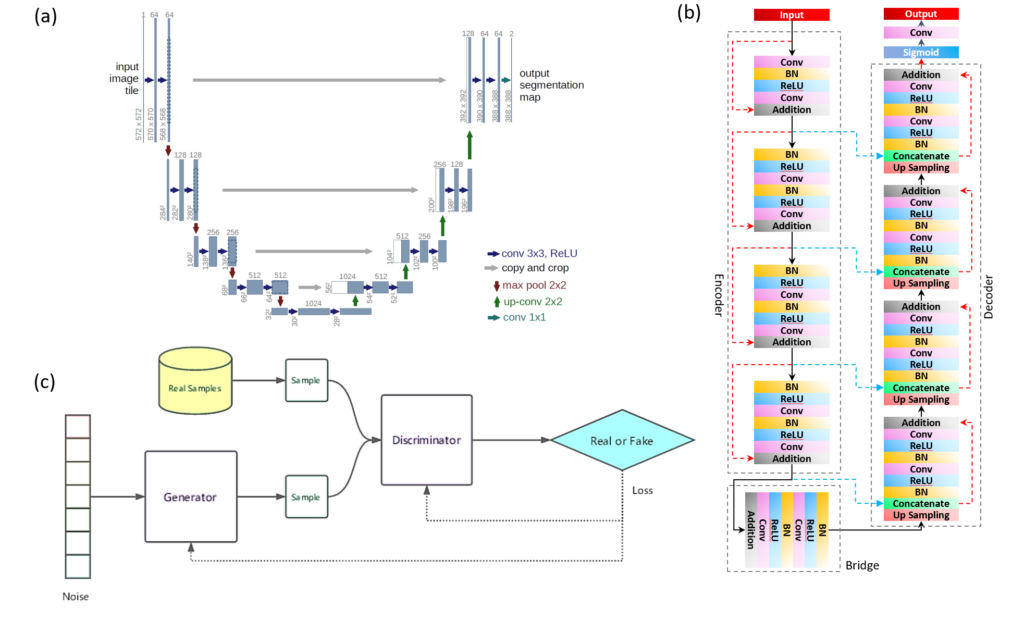
Figure 3 shows a representative problem of topology optimization. The ResUnet model will take the stress field (the six images outlined in red) and generate the binary output. Usually, the optimized structure is generated such that the structure can safely handle applied stress. The necessary information is embedded in the input stress fields. Hence, a successful ResUnet model would learn from the embedded information and predict the target structure.
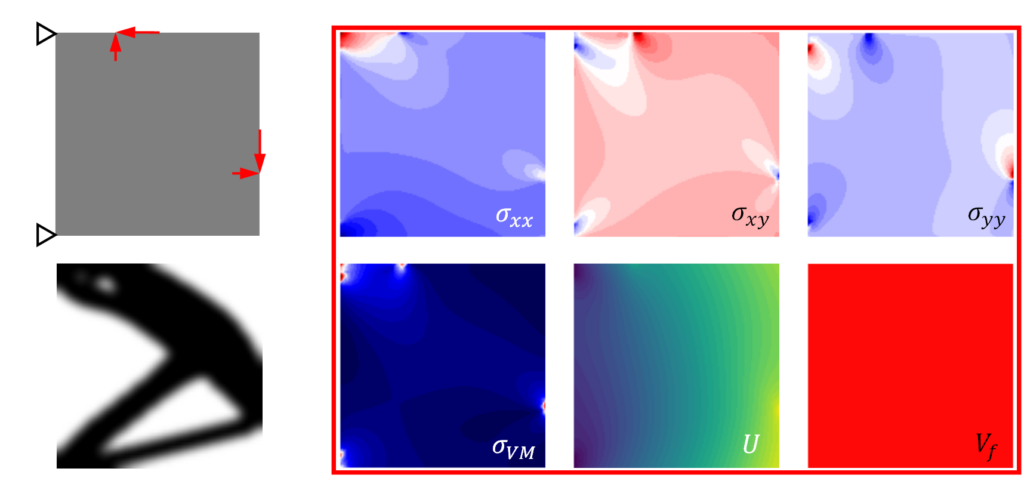
The objective of the ML would be to use inputs to segment the binary image (lower left image). In other words, it will try to find a correlation between high-stress region from the input and correlate 1 (black) and low stress as 0 (white).
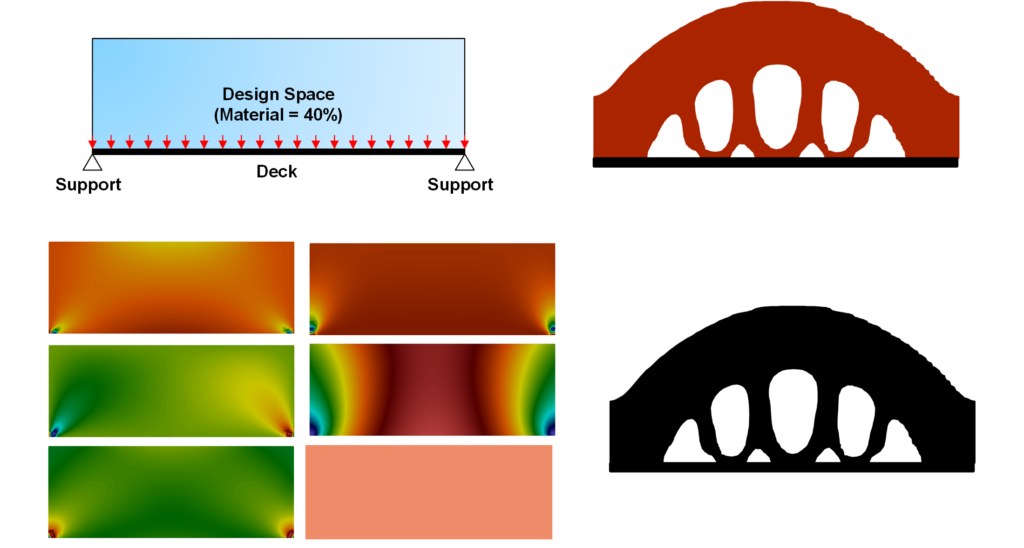
Figure 4 shows an example of how topology optimization can be accelerated using ML. The design domain is shown in the top left. The top right (red bridge) shows the optimized structure generated by the topology optimization algorithm. The topology optimization takes more than 2 mins to generate such a structure. The bottom right shows an optimized structure predicted by the ML algorithm (ResUnet). It took 0.03 sec to predict such a structure. The colored images on the bottom left (the stress fields, displacement field and volume fraction) are used as input for the ML network. In this example, ResUnet model predicted the optimized structure 4000 times faster than the original algorithm.
Conclusion
This project aims to accelerate the process of structural optimization with the help of ML algorithms. I have chosen ResUnet model for this work. In this blog, I tried to introduce the options I considered and the reason behind choosing the ResUnet architecture. After I complete the project, we will be able to generate the optimized structure through ML instantly, given the stress fields (calculated from initial force). This result should have comparable accuracy as an optimization algorithm. The example shown in Figure 4 is a clear indication of how ML can help accelerate optimization calculation. However, it is important to note that ML algorithms are susceptible to dataset bias, and artifacts that might not be physical. The dataset needs to be carefully chosen. In future work, I will try to build a bias-free dataset that can work on several optimization problems.