By Megan Kane
Introduction
Should computational tools be used to assess student writing? Their use is certainly becoming popular, particularly in high-stakes tests like the GRE, TOEFL, and College Board placement exams. However, many writing instructors remain skeptical of automated scoring systems, and the use of computational scoring systems is also opposed by the Conference on College Composition and Communication (CCCC), the largest organization for college writing professionals.
As a writing instructor myself, I agree that computational tools can’t replicate human reading practices that are critical to good writing assessment. Still, as a digital humanities researcher I see the merits of computational text analysis to study significant language patterns within large text corpora.
In this blog post, I suggest this analysis can be leveraged to assist (rather than replace) current writing program assessment practices. My Fall 2022 Cultural Analytics Practicum project explored one possible application for these tools by asking: Can computational tools detect language patterns in student writing that correlate to high grades?
In the rest of this post, I’ll walk through the Python code pipeline I developed to explore my research question. My code is also available in full on this Github repository.
Data Context and Preparation
For this study, I used a collection of around 150 student papers written in Temple University’s First-Year Writing Program, and the grades given to these papers by the course instructor. The papers I collected were written portfolio-style, so each submission actually contained four papers: a reflection, a rhetorical analysis, a topic exploration, and an argumentative essay.
Importantly, each portfolio was assigned a singular grade, so students were assessed based on how they conducted a variety of writing tasks. My study aimed to computationally identify and analyze language patterns correlated with students’ success in two of these tasks: 1) use of rhetorical terminology to analyze a source and 2) identification and engagement with arguments used in secondary sources.
To prepare the data for analysis, I converted the original versions of all papers (.docx files) to .txt format so they would be readable by Python. I uploaded the documents and scores to Google Colaboratory, a browser-based tool for running Python code, and organized them in a Pandas data frame (similar to a spreadsheet or table). Before conducting analysis, I used the Natural Language Toolkit to remove all instructor and student names from the essays and conduct some basic cleaning (lowercasing, punctuation removal and stop-word removal). I also segmented each text into paragraphs, since my pipeline aims to identify the immediate contexts within which students were using language to conduct the two tasks of interest.
Linear Regression of Rhetorical Terms Across Papers
To determine what types of language computational tools could identify that indicated the successful performance of rhetorical analysis, I turned to the course’s syllabus and assignment guidelines. Three classical rhetorical terms featured prominently and were clearly expected to appear in student work: “pathos” (the appeal to emotion), “ethos” (appeal to credibility) and “logos” (appeal to logic). As such, I conducted a computational keyword analysis of these terms to see how frequently they appeared in each portfolio.
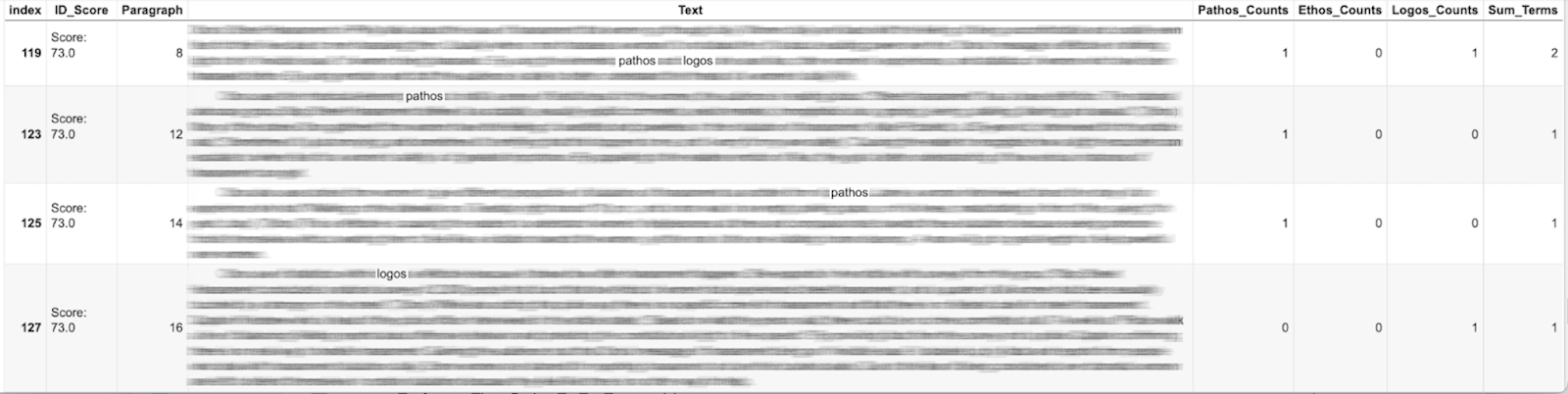
Regression analysis revealed a weak positive correlation between the use of rhetorical terms and high scores (R-squared=0.025; 2.5 percent of the variance in essay scores can be explained the model). In essence, the rhetorical term usage is not a strong predictor of essay score. As the regression plot shows, rhetorical terms were used to varying degrees across all grade ranges:
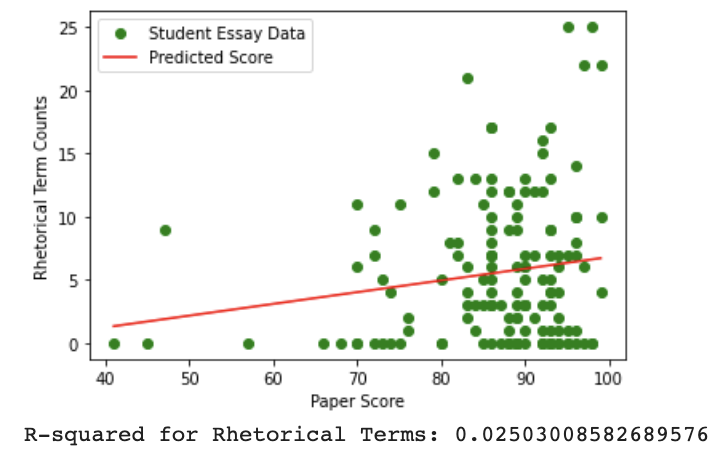
Such analysis indicates that computational identification of rhetorical analysis terminology cannot strongly predict instructors’ scores. In short, simply counting words–even ones instructors prize in the classroom–cannot significantly explain why instructors are making certain scoring decisions. This also tells students not to expect high scores simply because they use these terms frequently in their writing.
Along these lines, it is critical to note that these student portfolios are graded based on a constellation of factors, rather than their performance on a single task. Let’s look at another type of language that might better correlate to high scores: citation practices.
Linear Regression of Citation Practices Across Papers
To capture how students used language to engage with secondary sources in their work, I used two forms of computational analysis: string-detection of parenthetical citations and the tool DocuScope‘s metric for ‘citation’. First, knowing that students in this class used MLA citation style, which requires parenthetical-style in-text citations wherever sources are referenced, I ran code to search for parenthetical expressions used in the portfolios. I then removed parenthetical expressions without features indicating citation, like capital letters and/or numbers.
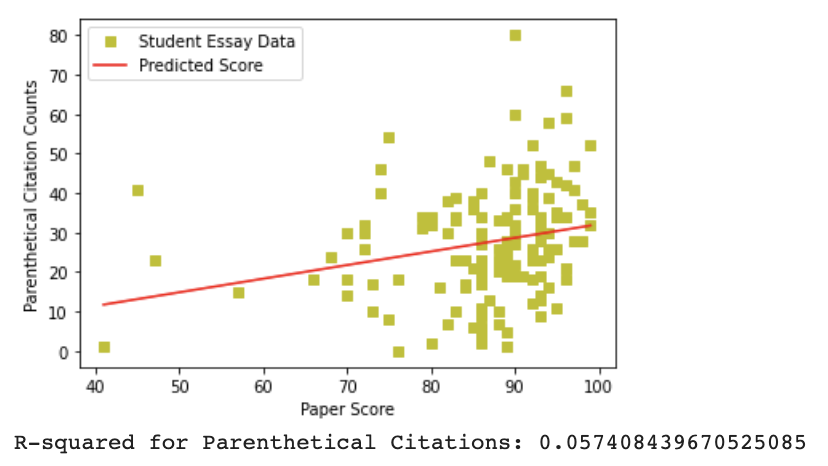
To complement this analysis, I used the DocuScope computational rhetorical analysis platform to identify language related to citation. DocuScope is a dictionary-based tool which “tags” texts based on a number of categories its authors deem as rhetorically meaningful. In this case, I was interested in the language DocuScope labeled as “Citation,” or language described as “statements that attribute words, thoughts, and positions to previous others.” Examples include “According to”, “based on,” and “as cited in”. This analysis was conducted outside of Python using the DocuScope desktop app, but the resulting file with citation language counts was uploaded to my script for analysis.
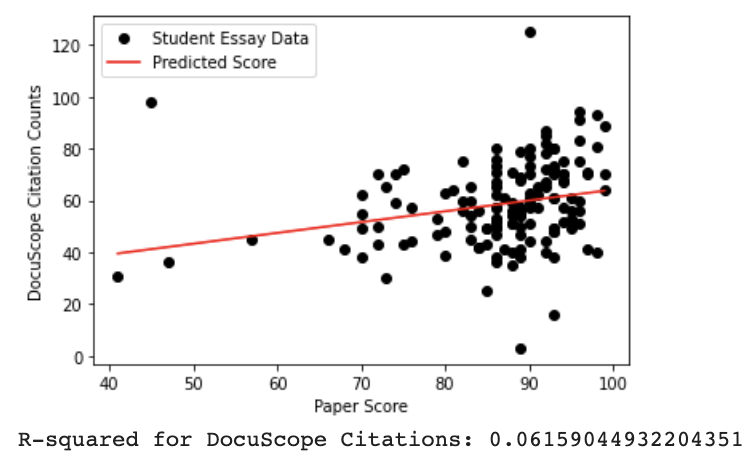
Both parenthetical citations (R-squared=0.057) and DocuScope terminology (R-Squared=0.062) had weak positive correlations to essay grades. However, both were stronger than rhetorical analysis terminology, signaling that there may be a significant correlation between citation practices and essay grades that could be further isolated with future study. For students, this indicates that it’s important to be aware of the number of citations used in a paper, while also attending to other factors (such as, perhaps, their quality) which are not quantified here.
Conclusions and Next Steps
So, can computational tools detect language patterns linked to score? My project reveals that the answer is complicated. Neither rhetorical or citation-based language was proven to strongly correlate to high essay grades. However, even low R-squared values may be significant when studying human behavior (like grading), and the weak correlations yielded interesting insights about the relationship between score and language use for instructors and students. The data set used in this pilot study was also limited in size and spread (e.g., there were far more A- and B-range essays than C- and D-range grades). Research using a larger, more representative dataset could yield more accurate results.
In future study, my plans include include: 1) broadening the types of terms I’m counting as related to analysis or citation, 2) calculating the correlation between grades and students’ usage of both rhetorical and citation practices, using ANOVA or PCA, 3) investigating language features related to other valued writing tasks, like argumentation, and 4) more comprehensively studying the contexts in which students are utilizing rhetorical terms, citations, and other language practices. Ultimately, this project encourages my continued exploration of how computational tools can help us develop more robust ways of analyzing and assessing student work.