By Andrea Siotto
This article is the second of a series on the project of making a map with all the ships sunk during the First World War
In creating the map of the ships lost during the First World War there are two major steps: scraping the data from Wikipedia and retrieving the coordinates from the descriptions when they are not already present. Since there are more than 8 thousand ships the key is to automate as much as possible. By hand, if we consider an average of 5 minutes of work per ship, the total would be more than 600 hours without automation. No way that I have the time for that (or the patience).
In this article we will review the web scraping, which is the collection of the data from webpages, in our case Wikipedia. I did not know Python, so I decided that it was a perfect occasion to learn it. It is an easy and forgiving programming language; in addition, it is often used for this kind of task and offers powerful and easy instruments for interacting with internet data.
At the bottom of the article you will find the overly commented code, so if you are interested only in seeing how I solved this problem you can jump directly there.
If instead you are in the middle of the planning of your project, a few considerations:
- You have never programmed? Don’t be scared: it is easier than it seems and if you think that your project will take a lot of time to do manually, consider that in using Python you will learn a tool for the future AND save time.
- Be as simple as you can: use text files (specifically plain text) to store your data, so you can manually modify them and read them.
- If you already did not think to use them, use csv files (comma separated values – which are text files specified to store data), but use a character that you know will not be present (I used @).
- Use BeautifulSoup: it is a very powerful Python library to manage html code; most importantly it is broadly used and there are many tutorials online.
So you decided to scrape some pages, grab the data and collect it in an orderly fashion. Your goal has a great friend and a major enemy.
The friend is your browser, which can show the html source code of the page that you will use in your search.
The enemy is JavaScript, because it means that the data is not available directly in the code, and you will need to implement much more complicated programming (if you need to do this kind of task then look into Selenium, a library that uses Chrome to interact with the data: it is possible, but it requires more programming and is slower).
If you are still considering to copy and paste manually every line of data for your project, think twice, because in my case it would have taken most likely the whole day, while in a couple of hours of programming (I never used Python and Beautiful Soup and I had to learn them) and 4 minutes of actual scraping I had my text file with all the ships orderly put line by line with the name, the date of sinking, their country, in many cases the coordinates, and a description of the events.
The problem of the ships without coordinates was a much more complicated one, so I decided to use C#, a language that I know better. It will be analyzed in the next article.
Here it is the code :
'''
The program collects the names of the links, and opens all the pages,
then searches for every
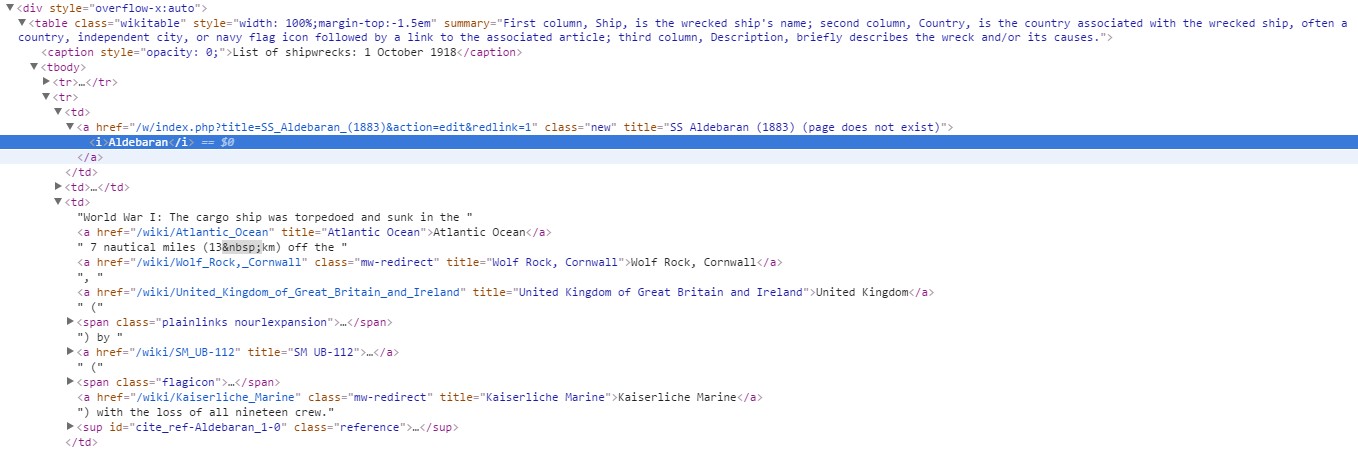
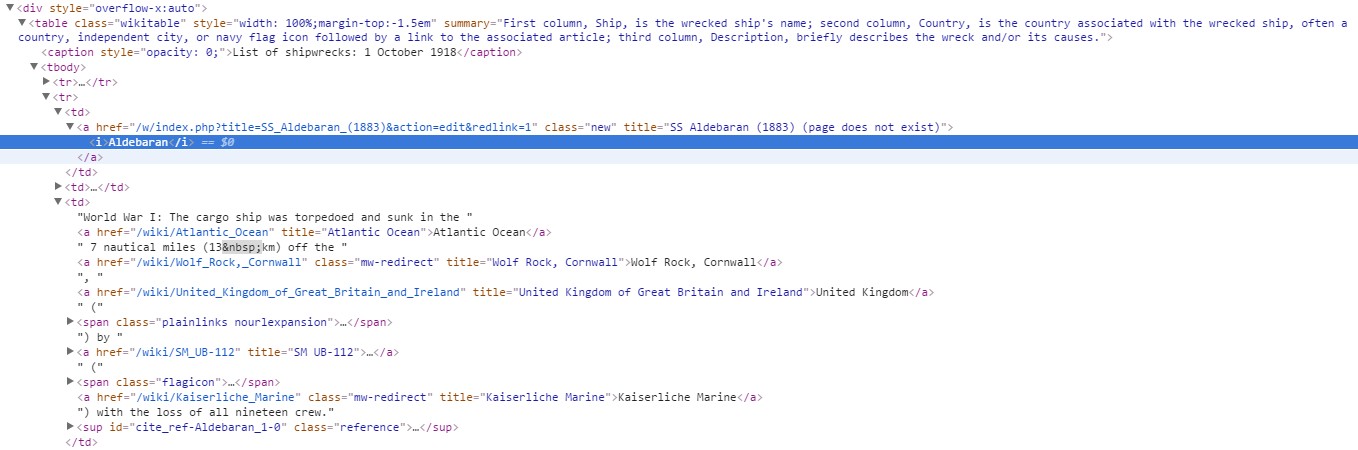
div style=”overflow-x: auto;”,
then for all of them grabs the text inList of shipwrecks: 3 August 1914
elaborate the string taking off the “List of shipwrecks:”
then collects all the(only if it hasand not)
PERHAPS NOT searches if the 3rdhas the coordinates and collects them
then writes a line on a file with all the text in theseparated by @ and followed by the coordinates
”’
def CheckLocation(Check_Link_Url,CheckLinkName): #filters the CheckLinkName string, and if passes the filter then scrape the page Check_Link_Url
FilterList =[“”,]
with urllib.request.urlopen(Check_Link_Url) as response:
data = response.read()
def search_for_overflow(soup):
for overflow_List in soup.findAll(‘div’, attrs={‘style’:’overflow-x:auto’}): # we search for the data. In our case the data we were looking for is always
#in a div with this specific attribute. these div represented each day of the month. They contained a table that listed all the ships sank in that date.
date = overflow_List.caption.text
date = date.replace(“List of shipwrecks: “,””) # cleans the title of the table for the day, to have the date in a simpler format
pretty2=overflow_List.prettify() # there must be a more elegant way, but I found simpler to create a new beautifulsoup objec for every div found
soup2 = BeautifulSoup(pretty2,’lxml’)
for List_tr in soup2.findAll(‘tr’):# for all the div found we search for the table rows
pretty3=List_tr.prettify() # and again we create a soup object of them
soup3 = BeautifulSoup(pretty3,’lxml’)
for index,List_td in enumerate(soup3.findAll(‘td’)): #then we search for all the cells
stringLinea =re.sub(r’\s+’, ‘ ‘, List_td.text)# we eliminate all the multiple spaces and transform them in single ones
stringLinea =re.sub(‘(\[\d+\])’, ‘ ‘, stringLinea)#then we delete the quotes like for example “[1]”
if index stringLinea=stringLinea+”@” # we add @ as character separator
stringLinea=stringLinea.replace(“\n”,””)# we delete the endline
with codecs.open(“List_Results_wikipedia_All_Pages_Plus_Coordinates and Names.txt”, “a”,encoding=’utf8’) as file:
file.write(stringLinea) #we write the cell on the file
else: # this is the more complicated fourth cell
stringLinea=stringLinea.replace(“\n”,””)
m = re.search(‘(?<=/).+(?=/)’, stringLinea) # we search for coordinates in the string
if m == None:
result = “”
else:
result = m.group(0) # result = the found coordinates
pretty4=List_td.prettify()# once again we create the object for beautifulsoup
soup4 = BeautifulSoup(pretty4, ‘lxml’)
stringLinks =”none”
if soup4!=None:
ListNameLinks = soup4.findAll(‘a’) #simplifying strategy: wikipedia often puts as a link interesting stuff in the texts, we search for them and store them
# to help the subsequent work
if len(ListNameLinks)==0: # there are not links in the text
stringLinks=”none”
else:
stringLinks=””
for index,element in enumerate(ListNameLinks): # put in a single string all the links, separated by the semicolon
if index
stringLinks = element.text
stringLinks = stringLinks.replace(“\n”,””)
else: # multiple links
textadd= element.text
textadd= textadd.replace(“\n”,””)
stringLinks = stringLinks+”;”+textadd
stringLinks =re.sub(r’\s+’, ‘ ‘, stringLinks)# in some cases the string still had multiple spaces, just for good measure we eliminate them
with codecs.open(“List_Results_wikipedia_All_Pages_Plus_Coordinates and Names.txt”, “a”,encoding=’utf8’) as file:
file.write(stringLinea+”@”+date+”@”+result+”@”+stringLinks+”\n”) # we organize the whole string as name@date@coordinates@the list of links in the text.
def main():
with open(“List_Results_wikipedia_All_Pages_Plus_Coordinates and Names.txt”, “w”): # this is the file where we will store all the data
pass
with open(‘List of Wikipedia links by month August 1914-December 1918’)as fileUrls: # we open the text file where we put all the web pages that we will scrape
addresses = fileUrls.readlines()
for page in addresses: # for every page we open it
with urllib.request.urlopen(page) as response:
data = response.read()
print(page)
soup = BeautifulSoup(data, “lxml”) # we create the beautifulsoup object
search_for_overflow(soup) # and we search for the data that we want with our function
if __name__ == “__main__”:
main()