
By Nicole Lemire-Garlic
With 91% of millenial and Gen-Z viewers on YouTube, non-profit organizations are increasingly promoting positive social change through compelling videos uploaded to the platform─a practice YouTube encourages. Yet, claims of YouTube’s recommendation algorithms directing users down unrelated rabbit holes or, worse, extremist bastions, proliferate.
How can a non-profit organization assess how YouTube’s algorithms will affect viewers looking at their uploaded videos? At the Scholars Studio, I’ve been testing out various computational text analysis methods that might help answer this question. In this blog post, I demonstrate a custom dictionary approach, implemented in the open-source software R, using a UNICEF child poverty video with over 3 million views.
A Dictionary Approach
Dictionary approaches to text mining are useful for locating specific words within a text. There are pre-set dictionaries designed to search for pre-determined topics. The LIWC, which contains lists of words linked to beliefs, thinking patterns, and personalities, among other things, is an example.
For this project, I did not locate a suitable pre-set dictionary of terms. So, to assess the similarity between the videos recommended by YouTube and the initial UNICEF video, I created a custom dictionary of words that reflect the “content” (see below) of the video. I culled the dictionary terms from the metadata of the UNICEF child poverty video.
Determining Video Content
Determining the “content” of a video is not as simple as it might sound. Humans can watch a video and pick out its general subject matter. For example, take a news broadcast showing cell phone footage of a police officer shooting a fleeing suspect. A human might classify this video as about “police violence” or “crime.”
How would a computer go about this task? There are some advanced applications in visual analytics designed for computers to view videos and analyze their images. But these techniques often require large amounts of sample data for testing, human coders for validation, and high-level coding. (Click here for a description of this process from the Universitat Osnabruck’s Institute of Cognitive Science). Textual representations of a video, however, are accessible and work well with tested computational tools. Enter: YouTube metadata.
YouTube Video Metadata
YouTube videos are categorized, marked and described in three primary ways:
- The platform places them in categories;
- Creators assign tags; and
- Creators name the videos with a title and provide a description.
Categories are, essentially, genre classifications created by YouTube. Each category has its own number and corresponding phrase, e.g., Entertainment (24) and Nonprofits & Activism (29). When a video is uploaded, YouTube assigns a single category to the video and it is displayed on the video screen, under the Description.
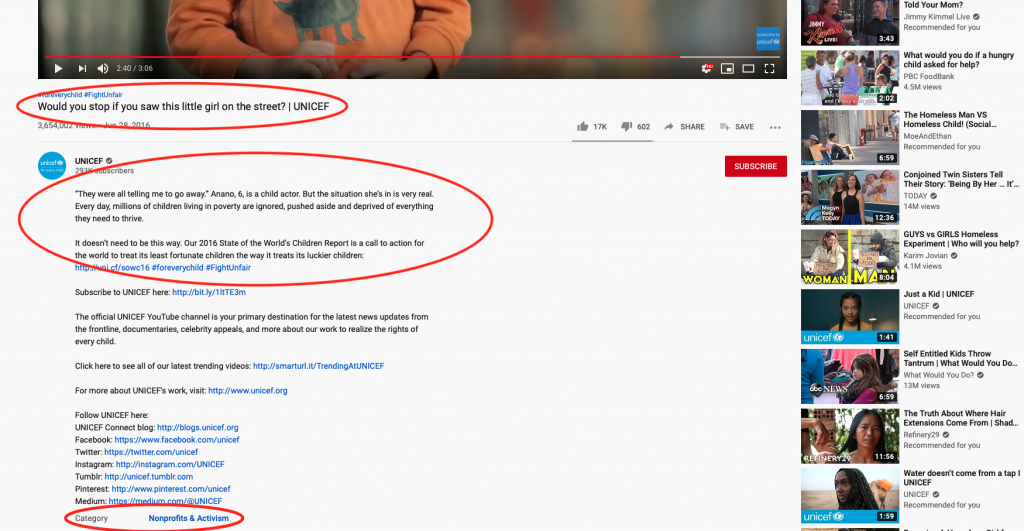
Tags are keywords crafted by the video’s creator (like “human rights” or “child”) that are used by YouTube to match videos to user keyword search entries. They work behind the scenes and cannot be seen on the YouTube interface. To see them, you have to access them through YouTube’s API. For marketing purposes, creators are encouraged to choose tags that represent what the video is of, or about, at its most base level. Some creators use them this way while others reiterate the creator’s name or video title, or incorporate target-market specific vocabulary. (Click here for the Tagging YouTube study, if you’d like to know more). There is no predetermined set of tags, and no standard number of tags used per video. And, because there is no universal taxonomy, creators may use different terms to refer to the same concept. Even so, tags can provide some insight into video content.
Titles and descriptions are also chosen by the video’s creator, and include keywords they believe will encourage viewers to watch. This suggests that video titles will contain, at least what the creator believes, is the central subject of the video. The description typically contains additional information about the video itself, but may also include links to the creator’s channel or other data unrelated to the video being promoted. Like the category, the title and description can be seen on the YouTube page.
Project Design
For this pilot project, I chose to focus on tags, titles, and descriptions like the researchers here, who used YouTube metadata to classify videos into emotion groups (e.g., happiness, fear, surprise). Categories appeared too broad to also be useful, but I included them in my analysis to confirm this hunch. Overall, I followed a three-step process: collecting the tags, title, and description for a list of 50 recommended videos with help from R’s tuber package and YouTube’s API, pre-processing and analyzing them with the custom dictionary I created, and visualizing the results with ggplot2.
Check out my next blog post to see how it all turned out.