By Nicole Lemire Garlic
As the world’s most utilized platform for video sharing, YouTube houses a wealth of culturally-relevant data that researchers and academics are only beginning to explore. Over one billion users view and upload videos on the platform each month. Part of what makes YouTube an interesting platform to study is its multimodality and intertextuality—each page includes multiple forms of mediated communication that refer to one another. Algorithmically-chosen recommended videos, user comments, and advertising videos appear dynamically on the same screen as the video originally posted for sharing.
At the Digital Scholarship Center, a group of graduate students and a postdoc hailing from communication and media studies, political science, and English (Alex Wermer-Colan, Ania Korsunska, Caroline Tynan, Jeff Antsen, Luling Huang, and I) have joined forces for a collaborative YouTube scraping project. Recent mediated images of the migrant caravan storming the U.S.-Mexico border led us to investigate national immigration and border discourses that circulate on the platform. We are exploring the ways in which content creators and users discuss immigration, asylum seekers, border security, and children held in immigration detention awaiting their, or their parents’, hearings. We’ve looked at various genres of videos, including news, advertisements, and music videos, with titles such as “Border patrol official: ‘Zero Tolerance’ Defense” and “Together is Beautiful.”
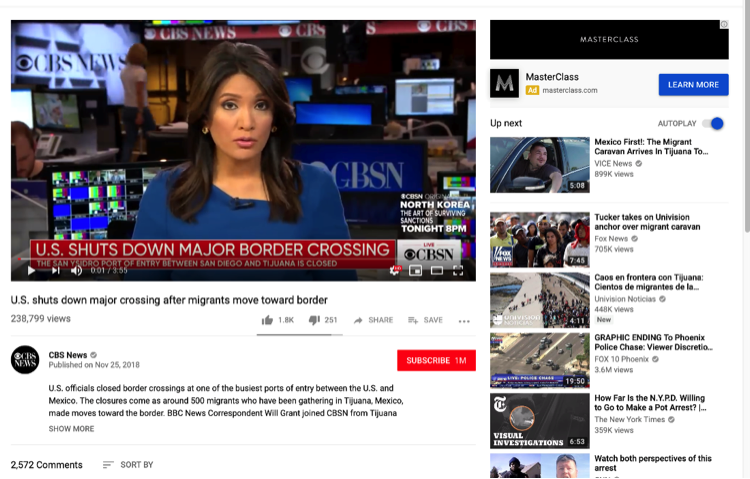
When approaching a project like this one, the sheer amount and variety of data produced on (and by) the platform can be overwhelming. Looking at the screenshot above for reference, there is the video news clip discussing the border crossing, the metadata about the video, the subscriber information about the YouTube channel on which the video is playing, the recommended videos highlighted by YouTube’s algorithms, and the advertisement in the upper-right hand corner of the screen. And, below the video, is a treasure trove of user comments.
Having worked with this patchwork of interwoven data for a few months, and having completed my own independent research analyzing race-related dialogue in YouTube comments discussing the 2018 Blank Panther film, I’ve culled some thoughts and tips on how to mine and analyze YouTube for all its worth.
Step One: Defining your Interest
When designing a YouTube project, a good place to start is Burgess & Green’s YouTube book for an overview of the platform’s history, how it works, and its cultural significance. From there, decide how you’d like to focus your study.
Here are some potential research foci, modes of analysis, and the relevant YouTube data. This chart is drawn primarily from the communication and media studies field, but English, political science, and other social sciences would find interesting questions to ask about YouTube as well.
| Research Interest | Modes of Analysis | YouTube Data |
| Content | ||
| Video content | Semiotic analysis
Quantitative content analysis Qualitative textual analysis Genre analysis Discourse analysis |
Videos (incl. likes/dislikes) |
| Comments content | Quantitative content analysis
Qualitative textual analysis Emoji analysis Topic modeling Word vectorization Network analysis |
Comments (incl. likes/dislikes) |
| Video recommendations | Quantitative content analysis
Qualitative textual analysis Network analysis |
Recommended videos
Video networks |
| In-Video Advertisements | Quantitative content analysis
Qualitative textual analysis Network analysis |
Comments
Video networks |
| Content creators | Quantitative content analysis
Qualitative textual analysis Network analysis |
Video metadata
Subscription data |
| Discourse | ||
| How is an issue framed? | Framing analysis | Comments
Videos |
| Who is interacting with this content, and how? | ||
|
Conversation analysis
Computer-mediated discourse analysis (CMDA) Network analysis |
Comment metadata
Usernames User icons Uploads User subscription data Geolocation data (with content creator’s grant of access) |
|
Semiotic analysis
Qualitative content analysis Network analysis |
Videos
Video metadata Video network |
Step Two: How to Scrape YouTube
Once you’ve decided on your project’s focus, and what type of data you need to collect, the next step is to scrape. One of the best open-source and user-friendly tools I’ve found is YouTube Data Tools hosted by the University of Amsterdam’s Digital Methods Initiative. The scraper uses its credentials to access YouTube’s APIv3, saving you the step of registering for your own Google access token. With this YouTube scraper, you can pull user comments, metadata about a YouTube channel, and videos via keyword search. You can also create networks of users, videos, and recommended videos. To scrape other types of data, such as images, you would need a different tool.
In this brief tutorial, I will focus on scraping user comments with YouTube Data Tools. With the few clicks of a button, the software will scrape comments, emojis intact. All you need is the video ID—the last few characters of the YouTube site for that video (e.g., SNWic0kGH-E).
What the scraper outputs is a neatly organized spreadsheet of the scraped comments alongside the exact time the comment was made, user information, and information about replies. The spreadsheet can be opened in Google Sheets. Using this data, a simple sort on the “replyCount” column can extract threaded conversations in order to focus on dialogue. Or, the comments alone could be concatenated into one large text file for topic modeling or other corpus analytics.

As we at the DSC continue working on our YouTube scraping project, we will look for what comments and other forms of YouTube data tell us about the changing nature of discourse around immigration and the border wall. Through our analyses, we will explore the way the YouTube platform shapes and limits the range of cultural discourse around politically-charged topics.
The use of web scraping here helps to extract only those information which is relevant. For instance, scraping information about competitor’s pricing strategies, client reviews, feedbacks of clients about various topics such as new product launches and so much more. All these can conduct quality actions to serve such clients more easily and quickly.