By Luling Huang
In my last post, I started to collect my data with the Chrome extension Web Scraper. I have included an expanded demonstration of how I used Web Scraper here (opens in new window).
The extension can get things done. However, I didn’t have enough control over what I want in my data set. Here are some of the troubles:
(1) I don’t have much control on what the data structure looks like.
(2) If some information is not displayed on the web, the visual-cue-based selectors of Web Scraper might not work. For example, I want to use ‘post ids’ to label each post, but the web page does not display the ids, which means that it is difficult to “click to select” with Web Scraper.
(3) If a tag has a child, and there are texts both under and outside the child, it is difficult to “click to select” only those texts outside the child with Web Scraper. Unfortunately, this is how the post contents are structured in html on the forum. This is crucial because I need to separate each post’s original content from its quoted content (if there is any).
(4) I can’t find a way to identify myself to the web server of the forum. This is important considering that identifying oneself is one of the scraping courtesies.
To deal with these issues, I turn to python. Inspired by Andrea Siotto’s (2016) post on scraping Wikipedia, I thought it was a good time to start learning python and to do some scrapings as exercise. I managed to write a scraper in python to get the data I wanted. It is doable in a few weeks once you have basic understanding of the python language, the data structures in python, the Beautiful Soup python library, and basics of regular expression. The rest is to google for troubleshooting.
I’m sharing my codes below and it might not be the most elegant way to do the work. If you have any ideas to improve the scraper, feel free to leave a comment. Also, I hope some parts of the codes would be useful if you are scraping similar websites, or come across similar troubles.
Due to the space limit, I am not going into details of what each line of code does. I will explain the general logic of my scraping based on the discussion of nested dictionary in python, and how I dealt with the specific troubles I mentioned above.
General logic:
(1) Store the scraped data in python as a nested dictionary.
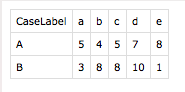
test={'A':{'a':'5','b':'4','c':'5','d':'7','e':'8'}, 'B':{'a':'3','b':'8','c':'8','d':'10','e':'1'}}
A basic dictionary in python is composed of multiple key-value pairs. Values of keys can simply be texts and numbers. The values can also be dictionaries. In this later case, inner dictionaries are nested under an outer dictionary. A simple two-layer nested dictionary is shown above. “test” is the outer dictionary, where ‘A’ and ‘B’ are the outer keys, ‘a’, ‘b’, ‘c’, ‘d’, and ‘e’ are the inner keys, and the numbers (as strings) are the values of inner keys. To make it more interpretable, ‘A’ and ‘B’ can be labels of two observations, ‘a’ to ‘e’ can be five attributes of observations, and the numbers can be measures of the attributes. If we write the dictionary into a csv file, it looks like this:
Note that we can reproduce the same csv file with the following lists:
cases=['A','B'] a=['5','3'] b=['4','8'] c=['5','8'] d=['7','10'] e=['8','1']
Why is a single nested dictionary preferred to a group of lists? Two reasons: (I) Lists are mutable in python. A list can be easily changed without knowing how changes are made. If, for example, the items in lists are somehow reordered, the resulting csv will present the data differently from the ways measures are originally recorded. If it is a nested dictionary, it is safer because the key-value pair is fixed after being recorded; (II) It is more efficient to search through a nested dictionary than a group of lists. Frances Zlotnick (2014) provides an excellent explanation on this matter.
In my case, the unit of analysis is post. Each post has a unique id number and 17 other attributes I’m interested in. Therefore, I assign the ‘post ids’ to be the outer keys and the 18 attributes as 18 inner keys.
(2) A big trunk of the codes below (from line 24 to line 125) is doing one thing: creating a list for each attribute containing information that will be used later as values of inner keys in the nested dictionary. This task includes locating the appropriate html tags, looping through the tags and retrieving information, and append each piece of retrieved information to the corresponding lists.
For example, lines 32 to 38 do the following: 1. create an empty list called “authorlist;” 2. locate all the
tags of the class “popupmenu memberaction” (because post authors can be found under these tags by examining the web’s source code), which returns a list containing these tags; 3. loop through this list: for each
tag, find the tags of the class “username online popupctrl” and the class “username offline popupctrl.” We need two classes of because the forum makes a distinction between post authors who are online and offline at the moment; 4. extract the author name and append it to “authorlist.” After looping, each author name becomes an item in “authorlist.”
(3) The next trunk of code (lines 132 to 157) loops through all the lists together, assigns post ids as outer keys, assigns attribute names as inner keys, and pairs inner keys with the values from the 18 lists just created.
(4) The nested dictionary is now created but it’s only for one page at the post level (there are 10 posts maximum on each page under a thread). Some threads have hundreds of posts. Also, at the thread level, there are also multiple pages (20 threads maximum on each page). In total, there are more than 1,200 threads as of 10/24/2016.
Therefore, the scraper needs to perform the following three tasks to deal with pagination:
A. Make a thread-to-post connection. After the scraper collects thread urls at the thread-level page, it will “click and open” each of those urls and parse it (see lines 11 to 22);
B. Loop through all pages at the post level under each thread until no “next page” button can be found (see the “while” loop statement at line 20, and lines 161-167);
C. When it finishes scraping at one page at the thread level, loop through following pages at the thread level until no “next page” button can be found (see the “while” loop statement at line 10, and lines 169-175).
(5) Writing the nested dictionary to csv (lines 177-213). The output looks like this:
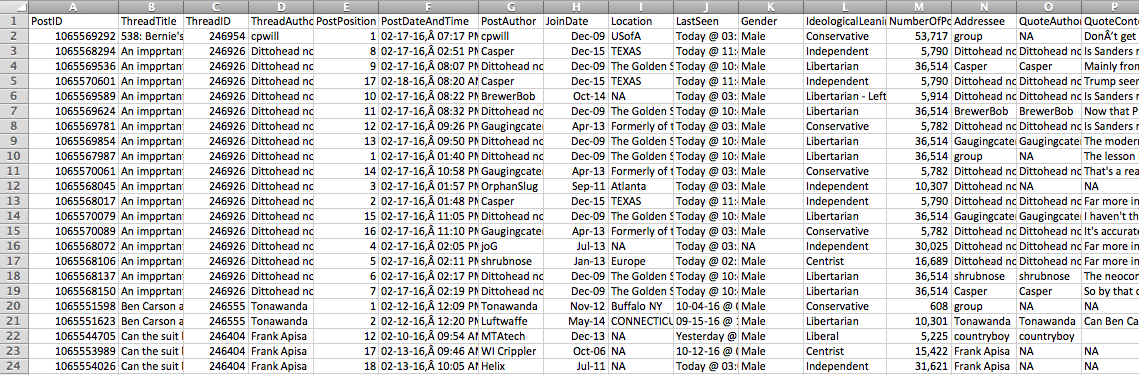
In this output file, I have already reordered the cases based on thread ids. With additional help of the attribute “post position” (a smaller number means an earlier reply under a thread), it is possible for me to reconstruct the temporal sequence of posts under each thread.
The last time I ran the scraper, I collected more than 43,900 posts. It took my personal computer about 4 hours and 40 minutes to run.
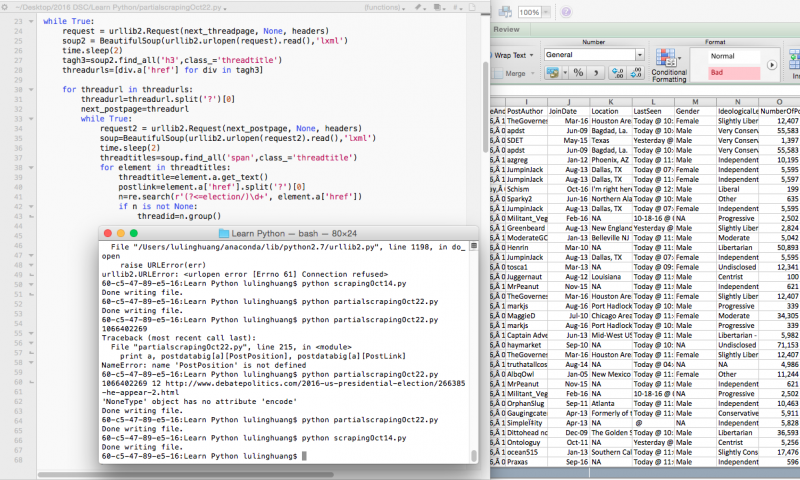
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 |
import time import re import urllib2 from bs4 import BeautifulSoup next_threadpage='http://www.debatepolitics.com/2016-us-presidential-election/' headers={'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3);Luling Huang/Temple University/luling.huang@temple.edu'} postdatabig={} while True: request = urllib2.Request(next_threadpage, None, headers) soup2 = BeautifulSoup(urllib2.urlopen(request).read(),'lxml') time.sleep(2) tagh3=soup2.find_all('h3',class_='threadtitle') threadurls=[div.a['href'] for div in tagh3] for threadurl in threadurls: threadurl=threadurl.split('?')[0] next_postpage=threadurl while True: request2 = urllib2.Request(next_postpage, None, headers) soup=BeautifulSoup(urllib2.urlopen(request2).read(),'lxml') time.sleep(2) threadtitles=soup.find_all('span',class_='threadtitle') for element in threadtitles: threadtitle=element.a.get_text() postlink=element.a['href'].split('?')[0] n=re.search(r'(?, element.a['href']) if n is not None: threadid=n.group() authorlist=[] divtagauthors=soup.find_all('div',class_="popupmenu memberaction") for element in divtagauthors: for postauthoron in element.find_all('a',class_='username online popupctrl'): authorlist.append(postauthoron.get_text()) for postauthoroff in element.find_all('a',class_='username offline popupctrl'): authorlist.append(postauthoroff.get_text()) postpositions=[] postcounters=soup.find_all('a',class_='postcounter') for postauthor, postcount in zip(authorlist,postcounters): if postcount.get_text()=='#1': threadauthor=postauthor for element in postcounters: postposition=element.get_text().split('#')[1] postpositions.append(int(postposition)) spandates=soup.find_all('span',class_='date') userinfos=soup.find_all('dl','userinfo_extra') joindates=[] locations=[] lastseens=[] genders=[] leans=[] postnumbers=[] for element in userinfos: if element.find('dt',string='Join Date') is not None: founddt1=element.find('dt',string='Join Date') joindates.append(founddt1.next_sibling.next_sibling.string) else: joindates.append('NA') if element.find('dt',string='Location') is not None: founddt2=element.find('dt',string='Location') locations.append(founddt2.next_sibling.next_sibling.string) else: locations.append('NA') if element.find('dt',string='Last Seen') is not None: founddt3=element.find('dt',string='Last Seen') lastseens.append(founddt3.next_sibling.string) else: lastseens.append('NA') if element.find('dt',string='Gender') is not None: founddt4=element.find('dt',string='Gender') if founddt4.next_sibling.next_sibling.find(src=re.compile('Female')) is not None: genders.append('Female') elif founddt4.next_sibling.next_sibling.find(src=re.compile('Male')) is not None: genders.append('Male') else: genders.append('NA') else: genders.append('NA') if element.find('dt',string='Lean') is not None: founddt5=element.find('dt',string='Lean') leans.append(founddt5.next_sibling.next_sibling.string) else: leans.append('NA') if element.find('dt',string='Posts') is not None: founddt6=element.find('dt',string='Posts') postnumbers.append(founddt6.next_sibling.next_sibling.string) else: postnumbers.append('NA') addressees=[] quoteauthors=[] quotecontents=[] originalcontents=[] postcontents=soup.find_all('blockquote','postcontent restore ') for postcontent,postcount in zip(postcontents,postcounters): if postcount.string=='#1': addressees.append('group') elif postcontent.find('div','bbcode_container') is None: addressees.append(threadauthor) else: for quoteauthor in postcontent.find_all('strong'): addressees.append(quoteauthor.string) if postcontent.find('strong') is not None: for quoteauthor in postcontent.find_all('strong'): quoteauthors.append(quoteauthor.string) else: quoteauthors.append('NA') if postcontent.find('div','bbcode_container') is not None: if postcontent.find('div','message') is not None: for quotecontent in postcontent.find_all('div','message'): quotecontents.append(quotecontent.get_text(' ', strip=True)) else: for quotecontent in postcontent.find_all('div','quote_container'): quotecontents.append(quotecontent.get_text(' ', strip=True)) else: quotecontents.append('NA') for element in postcontents: if element.find('div') is not None: element.div.decompose() originalcontents.append(element.get_text(' ', strip=True)) postdata={} toplitag=soup.find_all('li',class_='postbitlegacy postbitim postcontainer old') for (litagid,postposition,spandate,postauthor,joindate,location, lastseen,gender,lean,postnumber,addressee,quoteauthor, quotecontent,originalcontent) in zip(toplitag,postpositions, spandates,authorlist,joindates,locations,lastseens,genders, leans,postnumbers,addressees,quoteauthors,quotecontents,originalcontents): m=re.search(r'(?, litagid['id']) if m is not None: postdata[int(m.group())]={} postdata[int(m.group())]['PostPosition']=postposition postdata[int(m.group())]['PostDateAndTime']=spandate.get_text() postdata[int(m.group())]['PostAuthor']=postauthor postdata[int(m.group())]['JoinDate']=joindate postdata[int(m.group())]['Location']=location postdata[int(m.group())]['LastSeen']=lastseen postdata[int(m.group())]['Gender']=gender postdata[int(m.group())]['IdeologicalLeaning']=lean postdata[int(m.group())]['NumberOfPosts']=postnumber postdata[int(m.group())]['Addressee']=addressee postdata[int(m.group())]['QuoteAuthor']=quoteauthor postdata[int(m.group())]['QuoteContent']=quotecontent postdata[int(m.group())]['OriginalContent']=originalcontent postdata[int(m.group())]['ThreadTitle']=threadtitle postdata[int(m.group())]['ThreadAuthor']=threadauthor postdata[int(m.group())]['ThreadID']=threadid postdata[int(m.group())]['ThreadLink']=threadurl postdata[int(m.group())]['PostLink']=postlink postdatabig.update(postdata) try: nextpagetag=soup.find_all('a',attrs={'rel':'next'}) next_postpage=nextpagetag[0]['href'] except IndexError: break else: next_postpage=next_postpage.split('?')[0] try: nextthreadpagetag=soup2.find_all('a',attrs={'rel':'next'}) next_threadpage=nextthreadpagetag[0]['href'] except IndexError: break else: next_threadpage=next_threadpage.split('?')[0] import os, csv os.chdir("/Users/lulinghuang/Desktop/2016 DSC/Learn Python/") with open("scraping4TestOct23.csv", "w") as toWrite: writer = csv.writer(toWrite, delimiter=",") writer.writerow(["PostID", "ThreadTitle", 'ThreadID', 'ThreadAuthor','ThreadLink','PostLink', 'PostPosition','PostDateAndTime','PostAuthor','JoinDate', 'Location','LastSeen','Gender','IdeologicalLeaning','NumberOfPosts', 'Addressee','QuoteAuthor','QuoteContent','OriginalContent']) for a in postdatabig.keys(): try: writer.writerow([a, postdatabig[a]["ThreadTitle"].encode('utf-8'), postdatabig[a]["ThreadID"], postdatabig[a]["ThreadAuthor"].encode('utf-8'), postdatabig[a]["ThreadLink"].encode('utf-8'), postdatabig[a]["PostLink"].encode('utf-8'), postdatabig[a]["PostPosition"], postdatabig[a]["PostDateAndTime"].encode('utf-8'), postdatabig[a]["PostAuthor"].encode('utf-8'), postdatabig[a]["JoinDate"].encode('utf-8'), postdatabig[a]["Location"].encode('utf-8'), postdatabig[a]["LastSeen"].encode('utf-8'), postdatabig[a]["Gender"].encode('utf-8'), postdatabig[a]["IdeologicalLeaning"].encode('utf-8'), postdatabig[a]["NumberOfPosts"], postdatabig[a]["Addressee"].encode('utf-8'), postdatabig[a]["QuoteAuthor"].encode('utf-8'), postdatabig[a]["QuoteContent"].encode('utf-8'), postdatabig[a]["OriginalContent"].encode('utf-8')]) except AttributeError as detail: print a, postdatabig[a]["PostPosition"], postdatabig[a]["PostLink"] print detail continue print 'Done writing file.' |
Extract thread and post ids:
With Web Scraper, it was difficult to extract thread and post ids. In python, it is much easier. The post ids can be found in the “id” attribute of
- tags in the form of “post_##########”. An example:
- class=“postbitlegacy postbitim postcontainer old” id=“post_1065546074”>
-
To extract the ten-digit id, after locating the appropriate tags at line 137, I used regular expression to search for the pattern “##########” and extract the matched pattern at lines 138-139. In line 137, “(?Extract texts only under a parent tag:
Within a post, I need to separate quoted content (if there is any) from original content. These two kinds of content is approximately structured like the html in this hypothetical example:
class=“1”>
class=“2”> Quoted content (easy to locate and extract)Original content (tricky to <b>isolate</b>) </div>
It seems difficult to only select those texts outside the child tag. My first solution was to replace all children tags with “” (i.e., an empty string). There are two problems with this solution: (1) all text formatting tags would be removed. In the above example, the word “isolate” would be missed by the scraper; (2) sometimes a user would post links directly or post words with hyperlinks, which means there would be <a> tags in the original content. The texts enclosed in these <a> tags would be useful. I would lose this information with the first solution.
My current solution is to use Beautiful Soup’s “div.decompose()” to remove only the <div> tags (lines 122-125). It works because I’ve known that the quoted content must be within some <div> tags and the original content must be outside all <div> tags. With this solution, I can preserve as much information as possible.
Respect the scraping courtesies:
In essence, be nice to the server. First, I included “time.sleep()” at lines 13 and 23, which told the scraper to wait and rest after each request. Second, I ran the scraper during off-peak hours so that the scraper did not disturb too much other users’ access to the forum. Third, I identified myself to the server by including a header (lines 7, 11, and 21). You can find more information on scraping courtesies in Roberto Rocha’s (2015) article.
My next goal is to explore pandas, a python library for data cleaning and analysis. I had some troubles in converting a nested dictionary to DataFrame in pandas directly. I may have to write the dictionary to csv, and in a different python script, open and read the csv, then create a DataFrame from the csv. I’ll talk about it in the next post.
References
Rocha, R. (2015, March 8). On the ethics of web scraping [Blog article]. Retrieved from http://robertorocha.info/on-the-ethics-of-web-scraping/
Siotto, A. (2016, September 1). Web scraping with Python [Blog article]. Retrieved from https://sites.temple.edu/tudsc/2016/09/01/web-scraping-with-python/
Zlotnick, F. (2014). Hierarchical and associative data structures in python vs R [Web tutorial]. Retrieved from http://web.stanford.edu/~zlotnick/TextAsData/More_on_Dictionaries.html
Why not using https://scrapy.org ?
b4s is super cool, but I feel you are rewriting a web spiders.
Mmmh also to extract the post_id “post_1065546074” you don’t need regular expression, you can simply take the full string and then slice it using postId[5:]
See https://www.pythoncentral.io/cutting-and-slicing-strings-in-python/
Thanks for the comment! As a programming beginner, I found bs4 really easy to understand. I would definitely love to explore more about scrapy!
Yep, you’re right. Thanks!