
Written by Chuanzhu Xu
For a long time humans have dreamt of making a machine that can understand natural language to help us to do language translation, voice recognition and text analysis. But natural language is one of the most complex parts of information. This makes Natural Language Processing (NLP) a current hot research topic in Computer Science.
If you were asked the question, how machines could understand natural language, your first thought would probably be to let the machine simulate the human learning process; learning grammar, sentence analysis and so on. This was actually the idea of how to solve this problem in the 1970s. During that period, Noam Chomsky, one of the greatest linguists, came up with “Formal Language” Theory which tried to use a set of symbols and letters combined with some basic rules to define a language. Several people tried to solve natural language problems based on this theory. However, the formal language theory had its own weakness. The language described by this theory must be “well-formed”, which means the language has its own grammatical rule. As we known, the natural language sometime can be “bad- formed” and did not follow grammar structures. I think this is the main reason why there was not a breakthrough using formal language theory to solve natural language problems.

Back in the mid ’50s, Claude Shannon, a famous mathematician, proposed to use mathematical methods to deal with natural language. Unfortunately, at the time computing power could not meet the needs of information processing so most people didn’t pay attention to his idea. In the late 1980s a research team at IBM lead by Fred Jelinek first solved the speech recognition problem by using statistical models. Fred Jelinek was well known for his oft-quoted statement, “Every time I fired a linguist, the performance of the speech recognizer goes up”[1]. This revolution in NLP not only change the research field but also change the industry and our normal life. Due to this revolution, the accuracy of language translation and voice recognition raised to a new level brining many new tools to the world like Google Translate.
I will give an example about the Statistical Language Model. In many areas related to the natural language processing, such as translation, speech recognition, printing or handwriting recognition and documentation query, we need to know whether this series of words can be constructed to a meaningful sentence to the user. For this issue, we can use a simple statistical model to solve this problem.
S represents a series words in particular order w1, w2, …, wn. In other words, S may represent a meaningful sentence by this series of words. How can we check that? Computers will check P(S) possibility of S appearing in all of the “text”. The P(S) can tell you if the S is meaningful or not. By using conditional probability formula, the probability of this sequence appearing in the “text” is equal to the probability of each word appearing in the “text” multiplied.
![]()
P(w1) is the probability of w1 appearing, P(w2|w1) is probability of w2 in the condition that w1 appeared. So we can know P(wn|w1w2…wn-1) depends on all of the words appearing before . Computing this probability is too difficult, since we waste too much time computing single conditional probabilities. In order to make the computation easier, I will bring in the Markov assumptions, where the probability of only depends on the word before it. So after that, the P(S) will be pretty simple.
![]()
Right now, the problem is how to calculate the P(wi|wi-w1). Based on the formula,
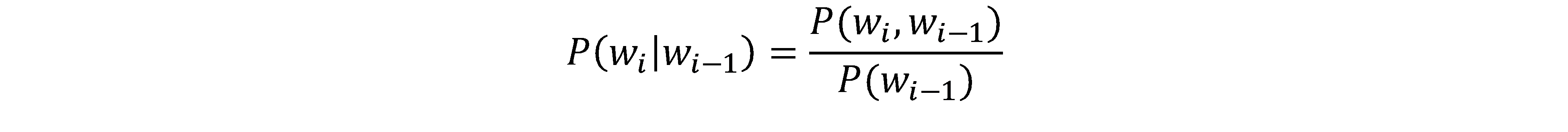
P(wi,wi-1) is the probability of these two words appearing together in “text”. You may still be confused with the “text” and how to calculate probability exactly. Actually, the “text” is all of the article we have stored in our database. If we want to calculate the P(wi), we just count the time wi appears and divide the number of total words in the article.
Many people still have difficulty believing that a simple module like this one could solve such a complicated problem, but Statistical Language Models is the best one available so far.
[1] Hirschberg, Julia (July 29, 1998). ‘Every time I fire a linguist, my performance goes up’, and other myths of the statistical natural language processing revolution (Speech). 15th National Conference on Artificial Intelligence, Madison, Wisconsin.Invited speech.
very useful articles, thank you