By Beth Seltzer
I believe that as digital methods grow in prominence, we’ll develop a huge collection of beautiful, correctly spelled, carefully curated texts for scholars to use for textual analysis.
The problem (as I point out in my earlier post) is that we’re not quite there yet. A lot of books are only available as messy OCR that’s never gotten any type of spell-checking, and other texts you have to OCR yourself from a PDF.
Fortunately, there are a few things you can do to clean up your texts without programming.
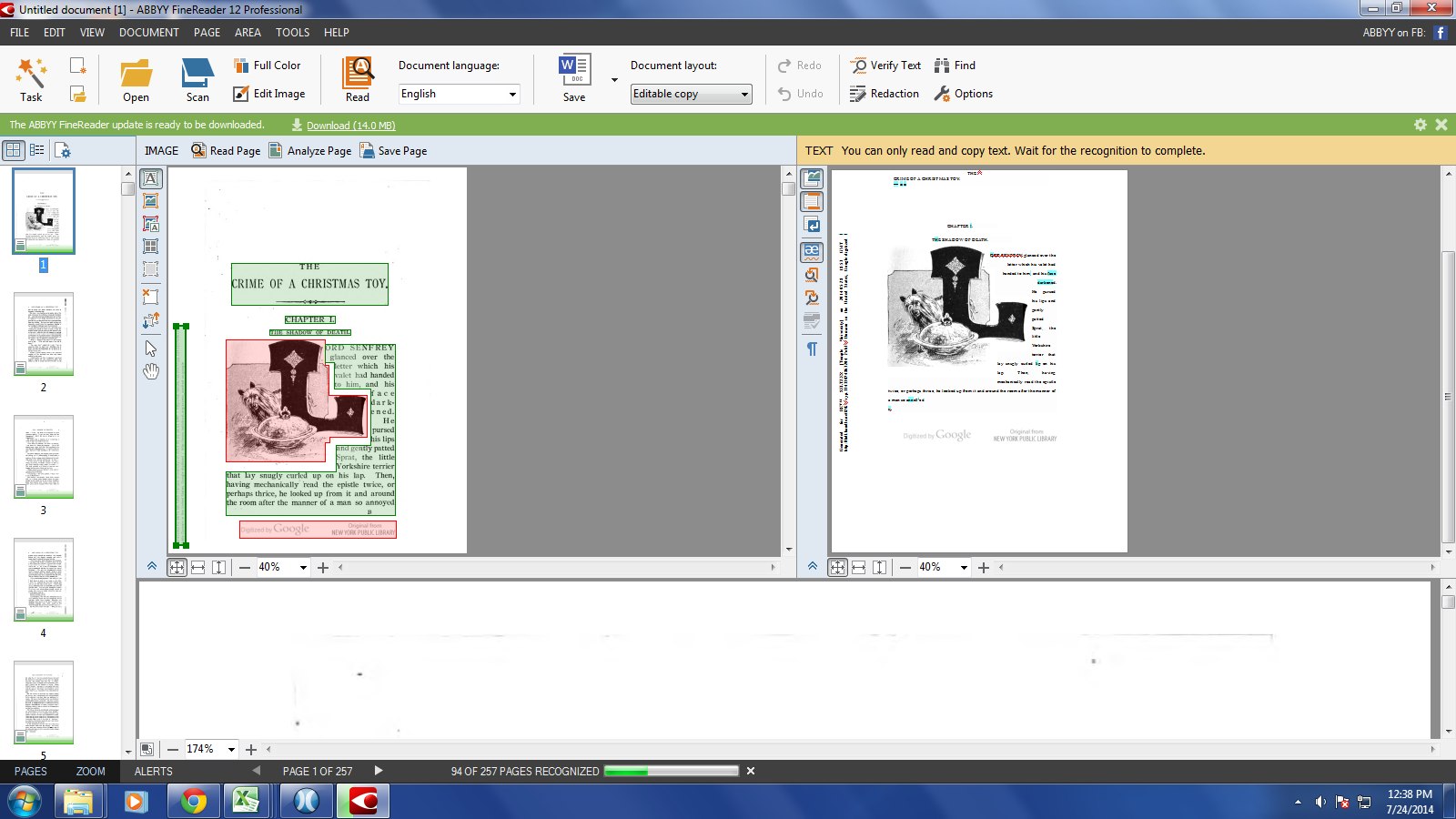
I used a program called ABBYY FineReader Pro to OCR my collection of Victorian detective novels that are only available as PDFs. I also tried out Adobe Acrobat Pro in an admittedly not particularly controlled experiment. I found they were both relatively accurate for OCR, but ABBYY FineReader was faster and more intuitive to use, which makes sense because it is just designed for OCR. I also tested out the Pro vs. the free versions of ABBYY with the help of one of our librarians, and discovered that the Pro version is significantly better than the free version.
One issue with OCRed texts is that old books often repeat the book title and/or chapter title on each page, and the computer will read these as text like any other text. And if your file repeats the title “Murder or Manslaughter?” two hundred times, it will significantly skew your textual analysis results! ABBYY solves this problem by automatically detecting page features such as headers and footers.
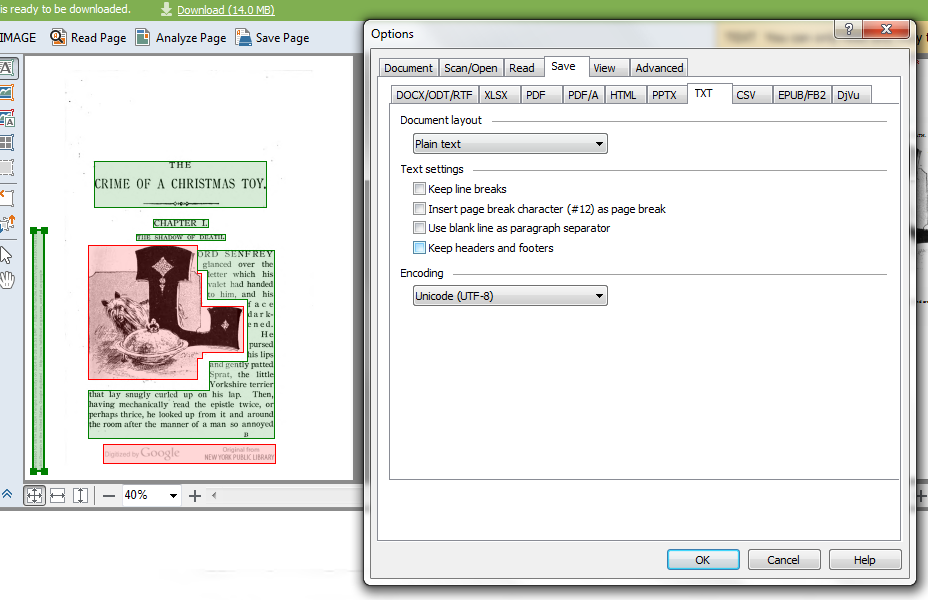
Then, you can change your settings so that headers and footers aren’t included when you create a text version of the file:
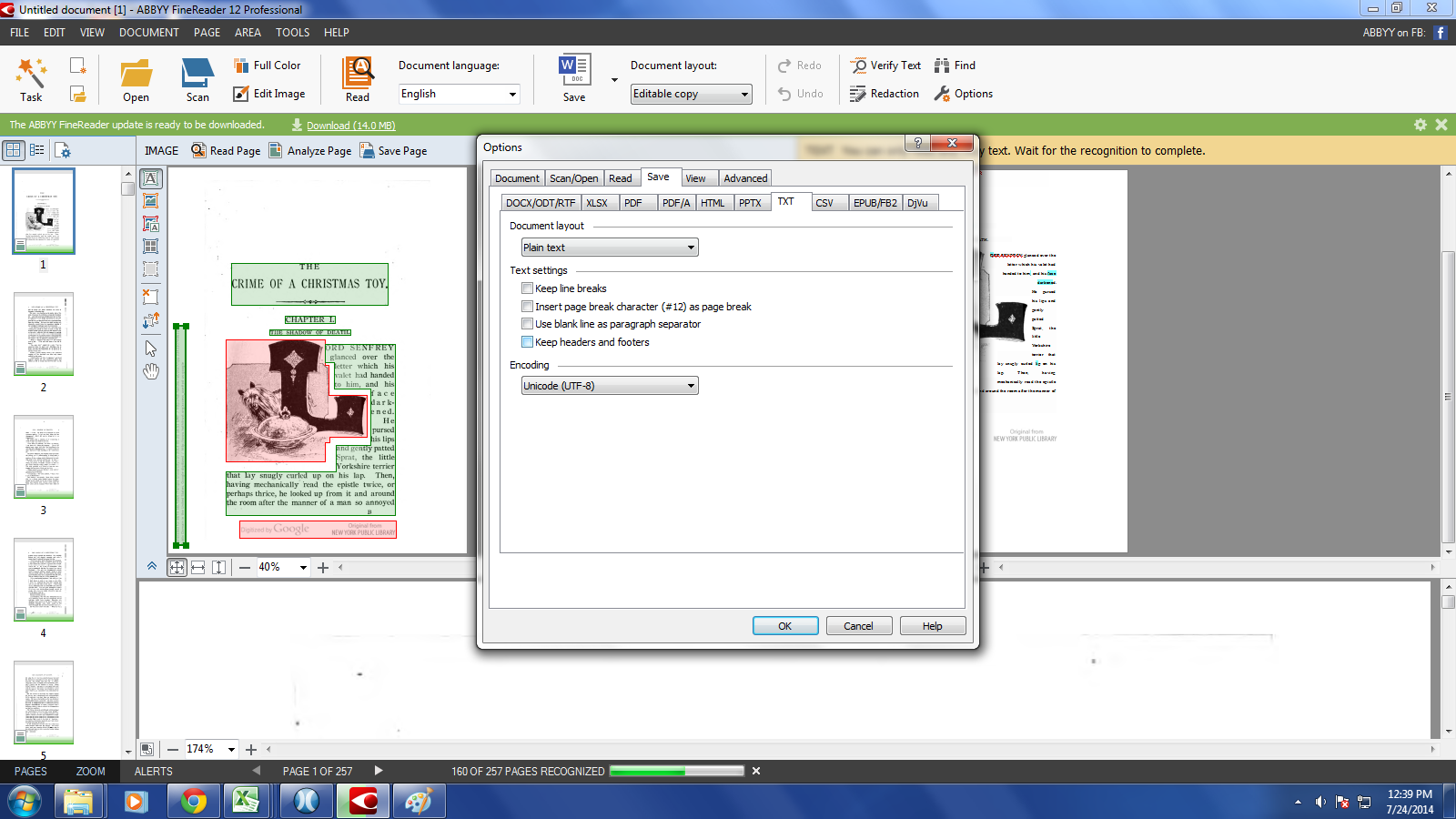
You can save your file in many different formats. I chose to save as plain-text, the format most often used for textual analysis. It’s still got plenty of OCR errors, but it looks a little nicer than the plain-text I got from the Internet Archive, and it only takes 10-15 minutes to OCR a book (depending on the size of your PDF).
But once everything’s OCRed, how do you spell-check it? You could check each text file individually—but even with a relatively small corpus of 200 novels, that would take weeks of work. You can speed up the process with a free program called Notepad++.
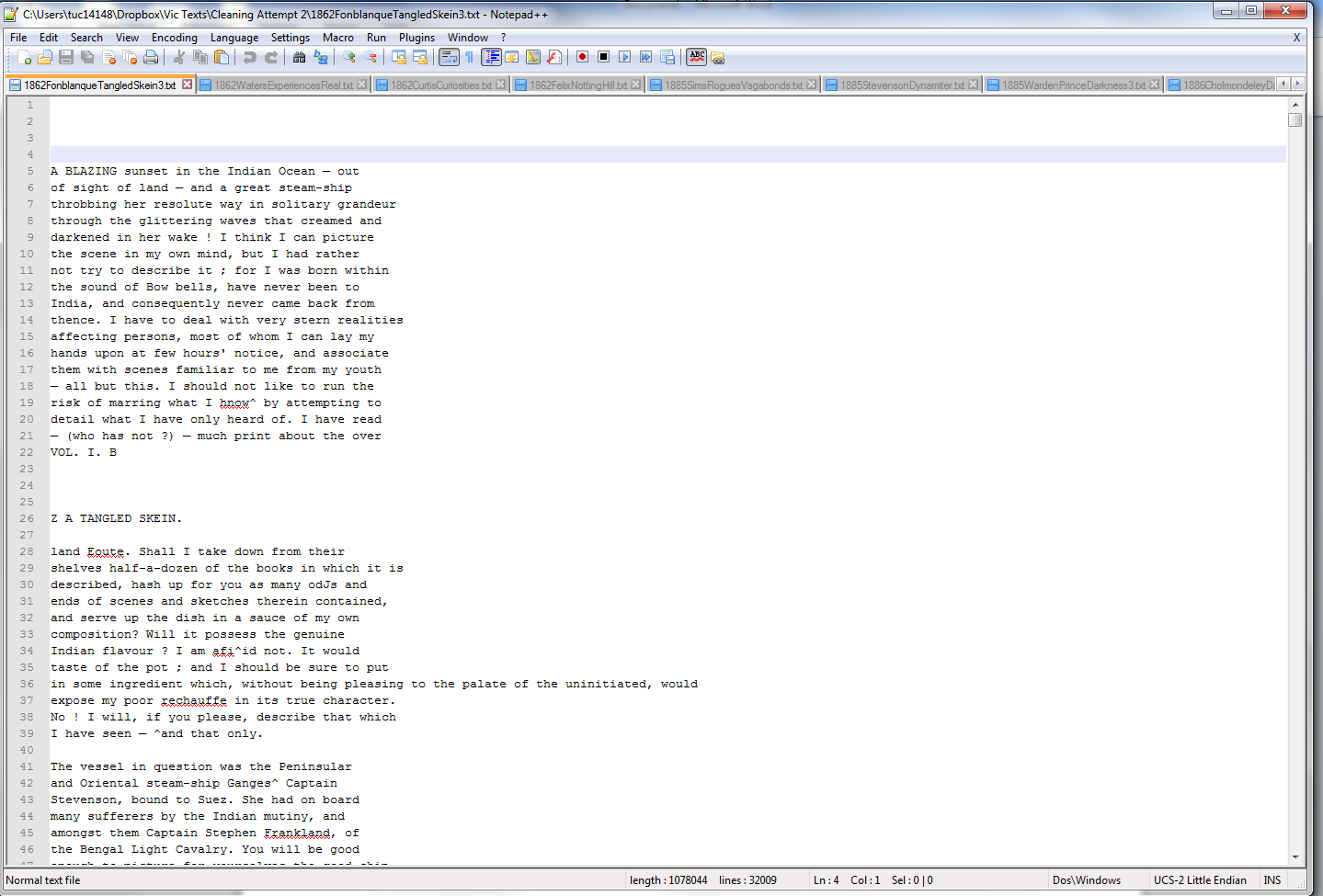
Not particularly fancy-looking, but this program will let you open all of your text files at once and do a find-and-replace on your whole corpus with just one step—a huge time-saver!
My sense is that we’re only a few years, at most, from a fancy spellchecker that will clean up your OCR automatically. In the meantime, here are some of the top corrections I needed in my 19th-century corpus:
- Remove all page numbers*: 55,776 corrections
- Recombine all hyphenated words beginning with com-, con-, in-, re-, and un-*: 8,002 corrections
- Recombine all hyphenated words ending with ment, tion, and ing*: 5,612 corrections
- Fix some common misspellings:
- delete ■ (960)
- bis -> his (422)
- delete “digitized by” (1331)
- liis -> his (250)
- tbe -> the (337)
- tiie -> the (698)
And so on!
*I did these more complex searches through something called “regular expressions.” Basically, instead of searching for and deleting every number individually: 1, 2, 3, 4… 301, 302, etc., you can tell the computer “delete all the numbers” by entering a short code you can look up on the internet. (In this case, the code is [0-9]+ ) Pretty convenient!