
By Beth Seltzer
Hi folks! I’m Beth Seltzer, a PhD Candidate in Temple’s English department, and I’m also a summer graduate student worker in the Digital Scholarship Center. My dissertation is on the intersection of nineteenth-century British detective fiction and new Victorian “informational genres,” like railway timetables and telegraph messages.
One of the things I get to do in the Center is to play around with different Temple resources and explore their implications for research. I’ve been using the HathiTrust, an 11 million-volume digital library which comes with built-in algorithms for analyzing the texts you find. For this post, I’m going to describe some of the messy, trial-and-error process of testing out the capacities of a new tool.
Maybe it will help with my latest dissertation chapter…
I started out with a topic I know pretty well from my dissertation research: Dickens’s The Mystery of Edwin Drood (1870). Dickens died halfway through writing it, and I’m researching the hundreds of completions and theories about the ending.
But it doesn’t quite work with the HathiTrust. When you cut out all the duplicates you’re left with only about 10 texts–it doesn’t have the richest database of Drood reserves. And that’s okay–different databases and tools work better for different things! For this topic, Temple’s database access to Nineteenth Century British Library Newspapers is much more helpful.
Or maybe I can use it to define the concept of the “detective.”
HathiTrust is a comprehensive resource, so maybe I can use it to trace the development of a concept over time.
One way to do this is to use Hathi’s built-in research portal to make topic models of different years. In topic modeling, the computer looks through more texts than you could humanly read and pulls out “topics,” i.e. collections of words that the computer thinks are related. (So, the computer might read a lot of books and put ocean, sea, ship, boat, whale, and captain all in the same category.)
I decided to start by searching for all of the texts which mention the word “detective” in 1830, and forming that collection into a dataset. Then, I made two more datasets for 1860 and 1890. Generally, you want to do little tests along the way to see if anything interesting pops up, before you invest too much time into prepping your collections.
When the results came back, I noticed some interesting things. For example, all three models showed what we might call a “political” topic, but this topic looks different in the different time periods:
1830: 
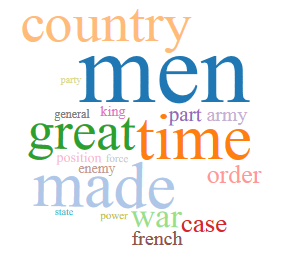
1890:

Look how the Irish pop up in the 1890s! And how “King” fades away with time, though it’s oddly not replaced by “Queen,” even though Queen Victoria took the throne in 1837. Perhaps this relates to Victoria’s domestic persona? Or to an increasingly middle-class society?
Of course, you’ll also find topics like this:

Did I just make an exciting find about the significance of “cloth” to nineteenth-century detective fiction? Nope, a topic like this one just means that most books ended with lists of advertisements for other books, specifying the price and the cloth covers of the books they were selling.
Anyway, I found some interesting things here, but these results aren’t really telling me anything about detectives or detection. (Even though I made this collection by searching for the word “detective,” detective doesn’t even make it to the top words list in any of these years.) New mission: find a detective theme!
Okay, looks like I’ve got to narrow down my corpus…
With a little effort, I assembled a reasonably edited collection of a little under 300 detective novels from 1830-1900. I ran another topic model on this collection, and this topic popped up:

Hooray! A “detective” theme at last!
Run tests on different authors to determine key themes.
But what if I’m really interested in comparing the themes of different authors? I tested this out by forming datasets of all of the texts from two very different Victorian novelists–Sir Arthur Conan Doyle, of Sherlock Holmes fame, and George Eliot, best known for Middlemarch and other works of high realism.
I should say that this is kind of problematic to begin with because HathiTrust has multiple copies of everything and their “author search” isn’t very precise. So if you do an author search for Jane Austen, who only wrote 6 novels (maybe 7.5 if you’re being generous), you’ll get 405 results. These results include things like secondary criticism, not just the novels. But it’s still interesting to see what results we get.
Sir Arthur Conan Doyle’s topics definitely displays his focus on rationality and crime-solving:

George Eliot doesn’t have any topics that look like this one. Instead, she’s got topics about feeling/sympathy/the soul, which is seems very true to form for Eliot:

While normally you want to start your project with a research question rather than a tool, this type of fun, trial-and-error experimentation is very useful for getting ideas and figuring out what’s possible. You can play around with HathiTrust tools yourself at the HTRC Portal.