
Goal:
Find the best matched polygons in a time series using a PostGIS Spatial Database
Background:
For previous project a comparison of housing data from the 1930s to current and historic US Census data was required. The geographic portion of the census data, was obtained from the National Historical Geographic Information System (NHGIS) which produces downloadable shapefiles with a GISJOIN field allowing for convenient linking of the shapefile to tables of census data also available through NHGIS. The 1930s housing data was in the form of an image of a 1937 Home Owners’ Loan Corporation (HOLC) map of Philadelphia available here. Very broadly the HOLC graded neighborhoods based on race/class and these grades where then used to determine the likelihood of housing loan assistance. There is debate if the HOLC process normalized race-based home lending practices and then the lead to further housing issues such as redlining. more info.
Process:
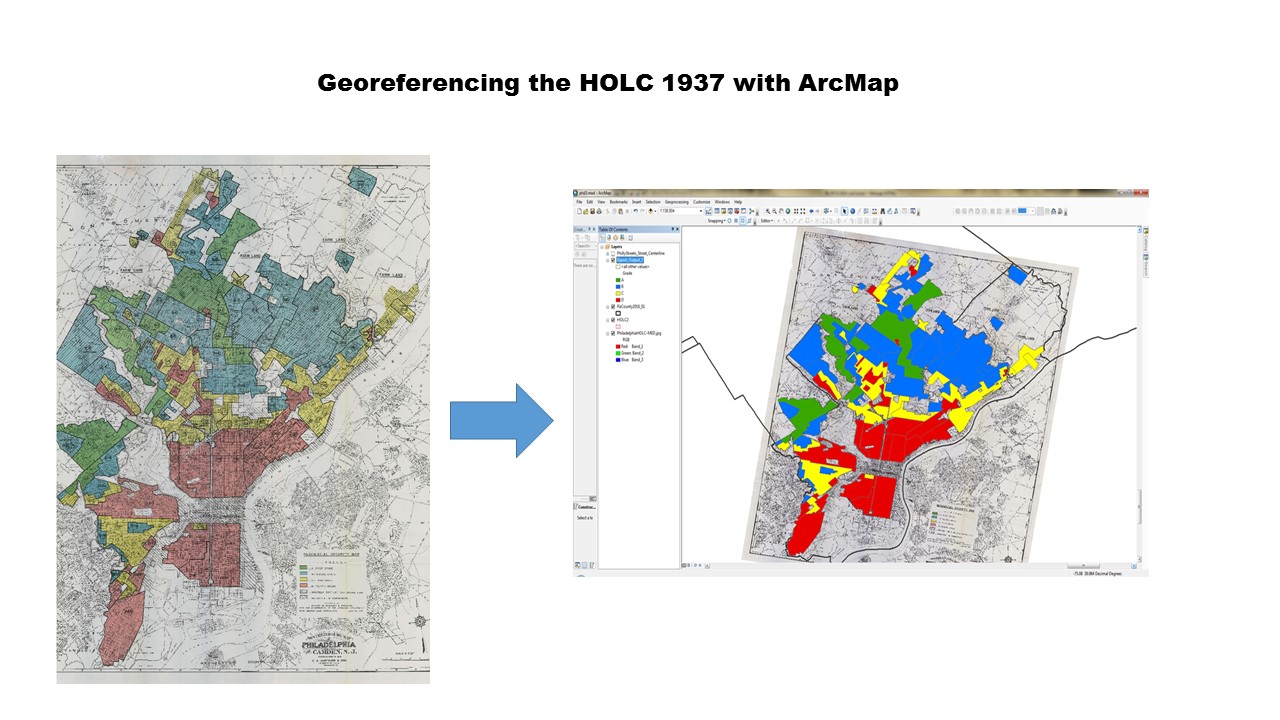
The HOLC map data was pulled into a GIS and a shapefile was created of the neighborhood grading (this process is often listed as ‘Heads-up Digitizing’ in job postings) here is a handy tutorial for ArcMap and another using QGIS. Shapefile and HOLC jpeg available on github.
The HOLC neighborhood grading schema does not coincide with any current (or historic) census arrangement so the spatial querying capabilities of pgAdmin and the PostgreSQL database engine was used to match the newly created HOLC digital data with the NHGIS Decennial Census geographic data.
Create a PostGIS Spatial Database and use pgShapeLoader to load the shapefiles (HOLC and NHGIS spatial data)
After much trial and error the following code worked the best:
create table overlap2010census as
with limited as(
select distinct us2010.*
from us2010, holc1937
WHERE ST_DWithin(us2010.geom, holc1937.geom, 0.25)
order by us2010.gid
)
/* the section above limits the query of the 2010 census polygons (Entire US) to those near the HOLC polygons –input can vary based on projection of files*/
SELECT DISTINCT ON (limited.gid)
limited.gid as us2010a_gid,
holc1937.gid as holc_gid, holc1937.name, holc1937.grade,
st_area((st_transform(limited.geom,4326)::geography)) as area_check,
ST_Area(ST_Intersection((st_transform(limited.geom,4326)::geography),
(st_transform(holc1937.geom,4326)::geography))) as intersect_area_2010_meters,
(ST_Area(ST_Intersection((st_transform(limited.geom,4326)::geography),
(st_transform(holc1937.geom,4326)::geography)))/
st_area((st_transform(limited.geom,4326)::geography)))*100 as percent_overlap,
/*calculates the area of the returned census and HOLC polygons and the percent of overlap */
limited.*
FROM limited, holc1937
where limited.geom && ST_Expand(holc1937.geom,1) and ST_Area(ST_Intersection(limited.geom, holc1937.geom)) >0
/* joins the files where the geom overlap*/
ORDER BY limited.gid, ST_Area(ST_Intersection((st_transform(limited.geom,4326)::geography),
(st_transform(holc1937.geom,4326)::geography))) DESC;
/* sorts by the largest amount of overlap, and in conjunction with the DISTINCT ON call
only returns the first instance of the census polygon that overlaps the target polygon */
While this method requires the user to update and repeat this code for each comparison the tables created can then be exported out to your GIS or QGIS can connect directly to your database if you prefer that option. As the query also created a unique identifier for each year and polygon of the Census data, a crosswalk/key table was created using this data which allowed for the Census data (race,income housing status etc.) for multiple years to be attached via the NHGIS GISJOIN field previously mentioned. Based off of the multiyear Census data attached via the crosswalk table comparisons of the HOLC geographic areas could then be made regardless of shifting Census borders.