Abstract
In a client-server ecosystem, sometimes perpetrators try to perform disruptive actions by flooding the server with malicious requests, thus causing it to slow down, and even stop functioning [1]. If there is just a single perpetrator causing the attack, the kind of attack is termed as a Denial of Service attack, in short DoS [1]. On the other hand, if the number of perpetrators is more than one, the kind of attack is termed a Distributed Denial of Service attack, (DDoS) [1]. This paper provides a detailed view of DoS attacks, DDoS attacks, their types, and brief information on countermeasures.
Introduction
In this modern era of global Internet connectivity, with the advancement in technology, there has been an advancement in unethical activities too [1]. There are several kinds of threats and attacks on the Internet because, during its commencement, the security underneath was not too emphasized upon [2]. Often termed the most severe of them all, Denial of Service and Distributed DoS attacks highly function on the fact that, disruption of this global connectivity is highly fatal to an immense number of high and low-end organizations [3].
The reason behind the high vulnerability to DoS attacks stems from two facts. Firstly, the know-how and tools for launching such an attack can be acquired from the internet and the skillset and expertise for launching one such attack can even be performed by a layman [1]. Secondly, knowledge pertaining to the detection and the prevention of such attacks, on the contrary, neither is readily available on the internet or other sources, nor is a layman’s task [1]. It requires technical know-how of the type, nature, and method of detection of the attacks [1].
The perpetrators of a DoS attack often control a node, by forging it with malicious software and controlling them, which are generally termed as attacking nodes or zombies, whereas the attacked nodes are termed as victim node [1], [2]. The mode of operation of this genre of attacks is to choke one or more of the operational resources of the victim node, by flooding it with an avalanche of unnecessary, often malformed data [2]. The operation of these attacks is discussed in the following sections of the paper.
This paper is organized as follows: Section II will attempt to classify DoS and DDoS attacks on the basis of various criteria. Section III will discuss the most prevalent countermeasures of the two attacks. Finally, Section IV will conclude the paper.
Classification of DoS and DDoS Attacks
The Denial of service attacks can be classified in different ways, based on differing criteria of distinction.
By the number of attackers and the flooded packet amount, DoS attacks may be broadly classified into two kinds: Software Exploits and Flooding Attacks [1].
Software Exploits: Also called Operating System-based attacks, these are the kind of attacks in which the perpetrator does not choke the victim node, but instead manages to halt its functionality by sending only one or a few potentially malicious packets [1], [3]. One major kind in this category is the Ping of Death (POD) attack, which is discussed later in Section II. of this paper, under the same paragraph heading [1].
As these kinds of attacks target the software rather than the processing functionalities of the victim node, keeping the software up-to-date is an efficient way of preventing them [1].
Flooding attacks: Also called network-based attacks, these are the kind of attacks in which the victim node is ‘flooded’ with a large number of packets of data, leaving no capacity to process anything else, then leading to a halt [1], [3].
Flooding attacks can be further classified into: Single-source and Multi-source attacks.
Single-source attacks are the ones that are seemingly caused by a single attacking node.
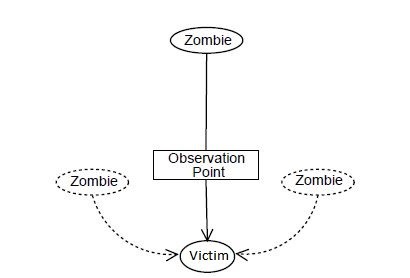
Figure 1: Single-source flooding attack [1].
As shown in Figure 1, there may be more than one zombie, but the terminology is set depending on how many can be perceived by the attacked victim node [1]. If it can perceive only one zombie or attacking node from the reference observation point, it is a single-source attack [1]. The dotted lines in Figure 1 indicate the zombies that have not been perceived.
Multi-source attacks are the attacks which can be perceived as being caused by more than one zombie or attacking node [1]. These attacks are also termed as Distributed Denial of Service attacks and will be looked into detail in the upcoming section III.6 [4]. By using multiple zombies, the volume of malicious packets is increased by a huge amount and hence is more disastrous [1]. It is also used to camouflage the main attacker [1].
ICMP or Internet Control Message Protocol is a protocol that sends error or information messages, in the case of any issues within a network connection between clients and servers. Reflectors are machines which, on receiving ICMP messages with the victim node’s IP address as the source, reply with an ICMP reply message, thus flooding the victim more and also camouflaging the attacking nodes [1]. Multi-source attacks are launched either by using more than one zombie or reflectors, along with the zombies.
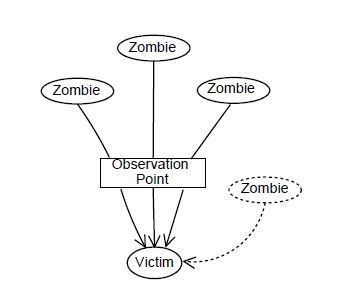
In Figure 2, the victim node perceives more than one attacking node via the observation point, and hence is a multi-source attack. But, there exist even more attacking nodes (shown via dotted lines) which still cannot be perceived.
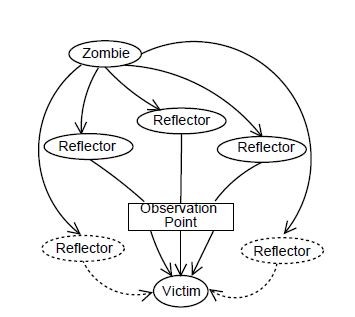
In Figure 3, the reflectors are perceived along with the zombie, through the observation point.
Getting into further detail, this paper analyzes a few of the prevalent DoS attacks and DDoS attacks.
SYN Flooding Attack: This form of attack targets the TCP protocol. Figure 5 below shows the process in which a 3-way handshake happens in the TCP protocol.
A client system sends a SYN message to a server system, which in our case is the victim node [3]. The server node sends back a SYN-ACK message to the client, which serves as a confirmation for the SYN message [3]. Finally, the client system sends back a final acknowledgment in the form of an ACK message [3]. Then, the data transfer begins.
For a number of SYN messages, the sequence numbers help in proper identification of the state at which the systems exist at a certain point of time [5].

In Figure 4, the second step is termed as a ‘half-open connection state’ [5]. In this state, the server node waits for the ACK message to come back from the client and sets a timer for this wait period [5].
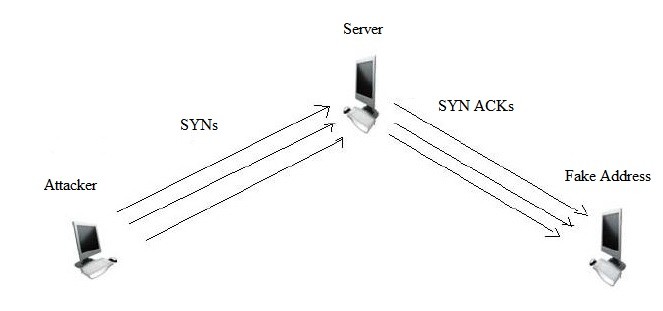
Figure 5 shows the situation when a SYN flooding attack scenario happens. In this case, firstly, the attacking node or zombie sends a large number of SYN messages with an incorrect address to the server or the victim node [5]. The victim node then sends out a SYN-ACK message for each of the SYN messages to the hoax address and waits [5]. But the ACK message never comes back [5]. As the queue for storing the waitlisted messages is limited, at one point of time, it fills up, and no more new SYN messages are taken into account, thus jamming the system [5]. However, this attack does not hamper outgoing connections as well as existing connections [5].
Ping of Death (PoD) Attack: This attack is generated on the basis of the fact that the maximum size of an ICMP message that the victim system can handle is 65,536 bytes [3].
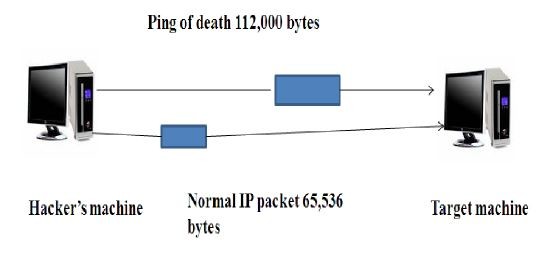
In this type of attacks, the attacking node sends a ping message much greater than 65,536 bytes (e.g. in Figure 6, 112,000 bytes) [3]. The TCP protocol transmits it fragment by fragment, and the victim node assembles it [3]. However, while assembling it, due to its huge size, the buffer at the victim node fills up and then overflows, eventually crashing the system [3], [6].
Smurf Attack: This is a destructive form of a DoS attack, slightly similar to the SYN flooding attack [8]. It uses the same approach of corrupting a 3-way TCP handshake [8].
In a Smurf Attack, the attacking node morphs an ICMP Echo Request message such that the source address is that of the victim node [8]. It then broadcasts this message along a remote LAN broadcast network [3]. All the active machines on the system will receive this message and generate an ICMP Echo Reply message, with the destination address of the victim node [8]. The more devices, the greater the flow of reply messages, ultimately jamming the network [8]. Furthermore, the attacking node might also incorporate the Ping of Death attack mechanism, generating a larger message size, such that the attack is all the more compelling [8].
Denial of Sleep Attack: This kind of attack focuses on the power consumption of the victim node [9]. The attacker targets solely the MAC layer protocol of the victim [9]. In wireless sensor networks, in order to decrease power consumption, the transceiver slips into ‘sleep’ mode, when not transmitting or receiving any message for a period of time [10]. The ‘denial of sleep’ attacker keeps the transceiver active constantly and does not let it go into ‘sleep’ mode, which highly reduces the durability of the device, and is thus potentially harmful to the victim node [10].
UDP Flooding Attack: An UDP (User Datagram Protocol) flooding attack is somewhat similar to a SYN flooding attack, described before.
Here, the attacker node sends UDP packets with addresses of one targeted UDP device as the source address to another UDP device [11]. What the attacker does is that it links the echo service of one victim node to the character-generating service of the other victim node, generating a non-stop to-and-fro action among both the victim devices [11].
Distributed Denial of Service Attack: Also, termed as a multi-source attack, the Distributed Denial of Service attack is similar to a Denial of Service attack. In fact, it is a special kind of a DoS attack, in which the main attacking node, also called the master zombie, spreads control over many other systems, also called the slave zombies, and controls these systems to launch an all-in attack on a network [9].
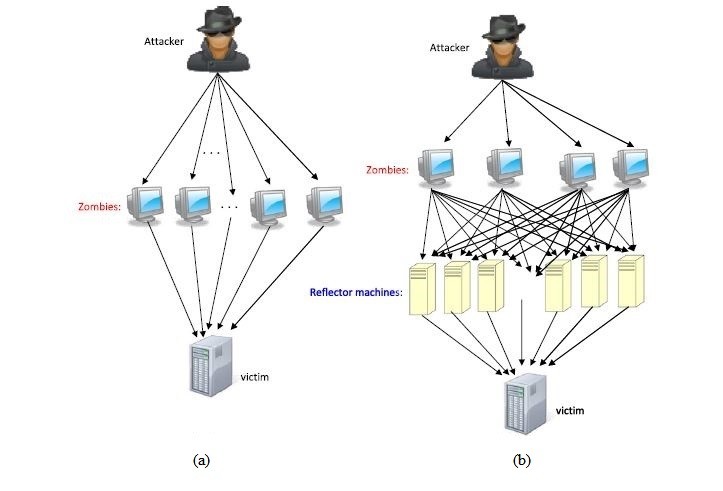
As discussed earlier in this paper, there are two main kinds of DDoS attacks. Figure 7 (a) shows a DDoS attack using multiple zombies [4]. Figure 7 (b) shows a DDoS attack using multiple zombies and multiple reflectors [4].
The main difference between reflector machines and slave machines (zombies) stem from the fact that the zombies are entirely controlled by the attacker or the master zombie, whereas the reflectors are independent machines, not controlled by the attacker per se, but support in the attacking scheme by unknowingly yet methodically serving as a magnifier to the attack, sometimes even helping in camouflaging the real identity of the attacker [1].
Countermeasures for DoS and Distributed DoS attacks
The detection of Denial of Service attacks require immense expertise, and hence, taking preventive measures is tough [1].
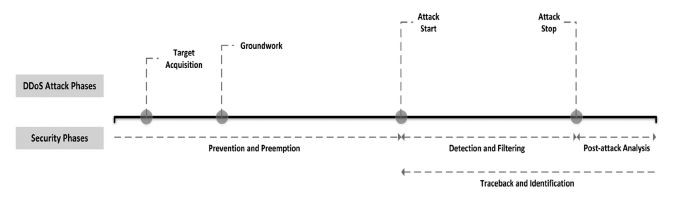
So, from Figure 8, we may classify a typical DoS or DDoS attack into four main phases. The first phase is ‘target acquisition’, where the attacker chooses a target; some choose financial transaction sites, like banks, some choose social media sites, some look for personal gain, even blackmail [11]. In the next phase, the attacker lays the ‘groundwork’. During this phase, the main attacking node, also called the master zombie, targets a number of other devices and takes them under its control, termed as slave zombies [1]. The third phase, the ‘attack start’ phase, involves the start of the physical attack [1]. If the type of attack involves reflectors, they are targeted during this phase [1]. Then, the main victim node is bombarded with the attack mechanism, depending on the type of attack [1]. The final phase is the ‘attack stop’, which most often ends well after the victim node has been rendered completely useless [1].
For a productive countermeasure method against DoS attack, there are certain phases of protection and detection to be followed in parallel with the attack timeline [2]. Before the attack actually happens, i.e., in the ‘target acquisition’ and ‘groundwork’ phases, all systems, that may turn into victim nodes, should take preventive and preemptive measures [2]. Once the system actually is under attack, there is no more space for prevention, but detection methods should be undertaken [2]. After that, comes the post-attack analysis to assess the effect of the attacks [2].
A number of methods for defensive actions against DoS attacks have been developed through the course of time [4]. These defense techniques can be further classified in a number of ways.
Classification according to the Points of Defense: The most basic way of classifying them stems from the area at which the method is implemented [4]. This yields to four sub-categories: source-end, core-end, victim-end, and distributed defense techniques.
Source-end Defense Techniques – As the name suggests, this method tries to stop malicious traffic at the source itself [4]. If the harm is stopped right at the source, there is no unnecessary burdening on the resources and also the problem is mitigated at its bud [4]. The downside, however, in this method stems from the fact that the source node has no information about the victim node, and hence maybe be partially or totally ineffective in blocking the actual malicious data [4].
Core-end Defense Techniques – In this kind of techniques, the defense mechanism is implemented in the routers amidst the traffic routes [4]. This method is effective for some of the flooding attack mechanisms where the attacking messages have a distinct feature, e.g. large message size [4]. But, apart from that, owing to the vast types of attacks prevalent, and the highly unknown nature of both the attacking node and the victim node, core-end defense mechanisms are not overall efficient [4].
Victim-end Defense Techniques – The victim-end techniques are highly targeted to the proper mechanism for the proper attack type [4]. However, at this point, the defense for the kind of attacks that target resource-overflowing as their mechanism, is inefficient, because, by the time these attacks reach the victim node, resources such as power or bandwidth have already been filled and, hence, compromised [4].
Distributed Defense Techniques – These are the techniques that merge efficiency and functionality at two or more of the former techniques, i.e., source-end, core-end and victim-end techniques [4].
Classification according to the Time of Reaction: Another way of classifying defense mechanisms is basing on the reaction time, i.e., at which stage of the happening of the attack do these defense mechanisms kick in [4]. This yields to three sub-categories: survival, proactive, and reactive defense mechanisms [4]. The survival and proactive techniques are the methodologies implemented well before the attack, and the reactive mechanism after the attack.
Survival Techniques – These techniques implement incrementing the resources and capabilities of the victim node, such that exhaustion of those by the attack is not feasible [4]. This can be achieved by introducing a number of proxy servers to back up the main server, increasing the size of the buffers and/or backlog queues, reducing the time-out duration for the connectivity requests or a combination of the above [4].
Proactive Techniques – These techniques stem from the fact that the attack is prevented even before the victim node gains knowledge about it [4]. Hence, these mechanisms are mostly placed in intermediate routers, which act in getting rid of malicious data, so that it does not reach the victim node [4]. But, the inefficiency in these techniques is often related to sifting the malicious packets from the huge amount of data to be processed, and that too in a time-efficient way [4].
Reactive Techniques – These techniques are adopted once the attack has started occurring [4]. The reactive methods happen at the victim node, which detects the incurring attack and then reacts accordingly [4]. Some of the mechanisms include generating alerts while the attack has been identified and rate limiting and/or resource limiting during the ongoing attack [4]. Some victim nodes follow a ‘divide-and-conquer’ strategy when attacked by a Distributed DoS attacker [4]. In this scenario, the victim node tries refuting the attacking zombies one by one [4].
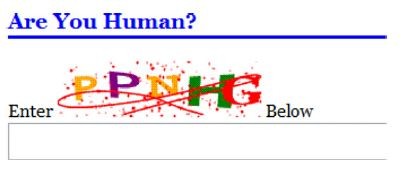
Some popular reactive techniques are the ‘Client-puzzle protocol’ and ‘CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) protocol’ [4].
Client-puzzle protocols pose one or more mathematical problems for the user to solve [4]. The problems are randomly generated from a large pool and thus cannot be programmed to be answered by a machine, hence stopping overflowing requests [4].
The ‘CAPTCHA’ puzzles are a specific kind of puzzles [4]. As shown in Figure 12, these puzzles generate random strings of characters for the user to type in [4]. This method is more efficient as the words can even be programmed to be meaningless and arbitrary, leaving no space for the attacker to program the inputs from before [4].
However, both of these methods have their respective downsides, e.g. they are relatively inefficient for resource overflow attacks [4]. Also, these mechanisms might backfire, themselves blocking data due to improper encryptions and, hence, acting themselves as Denial of Service [4].
Conclusion
Denial of Service and Distributed Denial of Service are prominent methods of launching attacks on server networks and are immensely harmful on almost every platform. These attacks target various kinds of resources, depleting them or rendering them ineffective. Techniques for encompassing these attacks also have been employed and are still under development. This has led to an ongoing tug-of-war, where techniques are being developed to counter the DoS attacks, and again newer forms of attacks are being launched, bending around those countering techniques.
References
[1] A. Hussain, J. Heidemann, C. Papadopoulos, “A framework for classifying denial of service attacks”, Proceedings of ACM SIGCOMM, Karlsruhe, Germany, 2003, pp. 99–110.
[2] K. Singh, P. Singh, and K. Kumar, “A systematic review of IP traceback schemes for denial of service attacks,” Computers & Security, vol. 56, pp. 111–139, 2016.
[3] K. K. More and P. B. Gosavi, “A survey on effective way of detecting denial-of-service attack using multivariate correlation analysis,” 2015 International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT), 2015.
[4] H. Beitollahi and G. Deconinck, “Analyzing well-known countermeasures against distributed denial of service attacks,” Computer Communications, vol. 35, no. 11, pp. 1312–1332, 2012.
[5] K. Geetha and N. Sreenath, “SYN flooding attack — Identification and analysis,” International Conference on Information Communication and Embedded Systems (ICICES2014), Chennai, 2014, pp. 1-7. doi: 10.1109/ICICES.2014.7033828
[6] M. Buvaneswari and T. Subha, “IHoneycol: A distributed collaborative approach for mitigation of DDoS attack,” 2013 International Conference on Information Communication and Embedded Systems (ICICES), Chennai, 2013, pp. 340-345. doi: 10.1109/ICICES.2013.6508281
[7] S. Kumar, “Smurf-based Distributed Denial of Service (DDoS) Attack Amplification in Internet,” Second International Conference on Internet Monitoring and Protection (ICIMP 2007), San Jose, CA, 2007, pp. 25-25. doi: 10.1109/ICIMP.2007.42
[8] G. R. Zargar and P. Kabiri, “Identification of effective network features to detect Smurf attacks,” 2009 IEEE Student Conference on Research and Development (SCOReD), UPM Serdang, 2009, pp. 49-52. doi: 10.1109/SCORED.2009.5443345
[9] K. N. Mallikarjunan, K. Muthupriya and S. M. Shalinie, “A survey of distributed denial of service attack,” 2016 10th International Conference on Intelligent Systems and Control (ISCO), Coimbatore, 2016, pp. 1-6. doi: 10.1109/ISCO.2016.7727096
[10] V. C. Manju, S. L. Senthil Lekha and M. Sasi Kumar, “Mechanisms for detecting and preventing denial of sleep attacks on wireless sensor networks,” 2013 IEEE Conference on Information & Communication Technologies, JeJu Island, 2013, pp. 74-77. doi: 10.1109/CICT.2013.6558065
[11] L. Garber, “Denial-of-service attacks rip the internet,” Computer, vol. 33, no. 4, pp. 12-17, Apr 2000. doi: 10.1109/MC.2000.839316